 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeString-based Molecule Generation via Multi-decoder VAE
Aug 23, 2022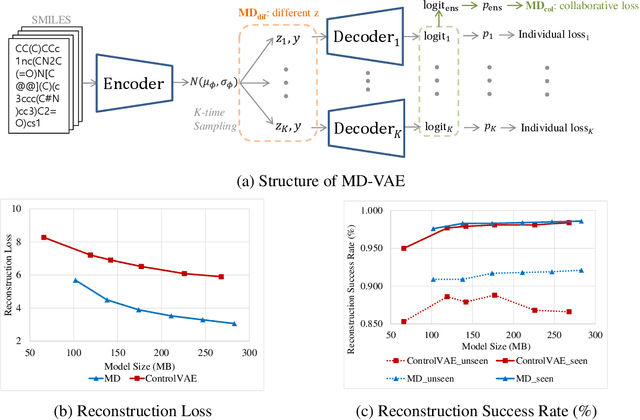
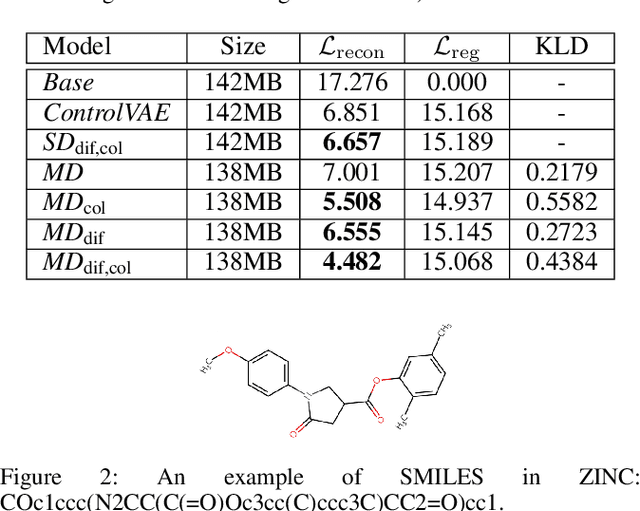
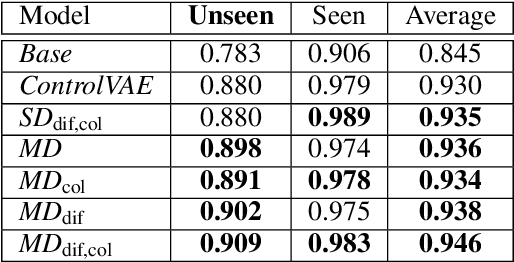
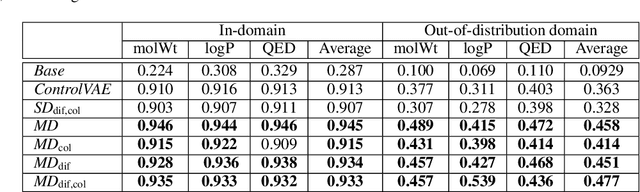
In this paper, we investigate the problem of string-based molecular generation via variational autoencoders (VAEs) that have served a popular generative approach for various tasks in artificial intelligence. We propose a simple, yet effective idea to improve the performance of VAE for the task. Our main idea is to maintain multiple decoders while sharing a single encoder, i.e., it is a type of ensemble techniques. Here, we first found that training each decoder independently may not be effective as the bias of the ensemble decoder increases severely under its auto-regressive inference. To maintain both small bias and variance of the ensemble model, our proposed technique is two-fold: (a) a different latent variable is sampled for each decoder (from estimated mean and variance offered by the shared encoder) to encourage diverse characteristics of decoders and (b) a collaborative loss is used during training to control the aggregated quality of decoders using different latent variables. In our experiments, the proposed VAE model particularly performs well for generating a sample from out-of-domain distribution.
SpeechBrain: A General-Purpose Speech Toolkit
Jun 08, 2021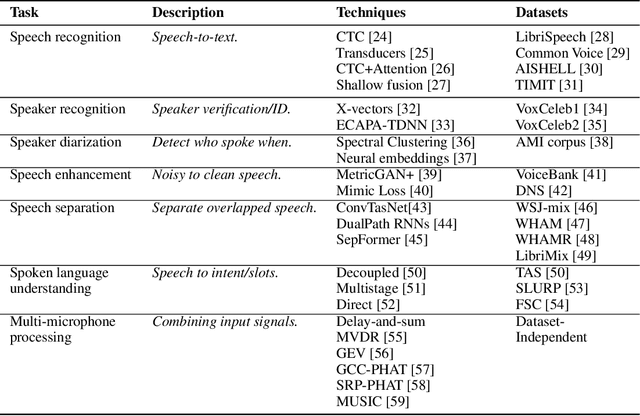
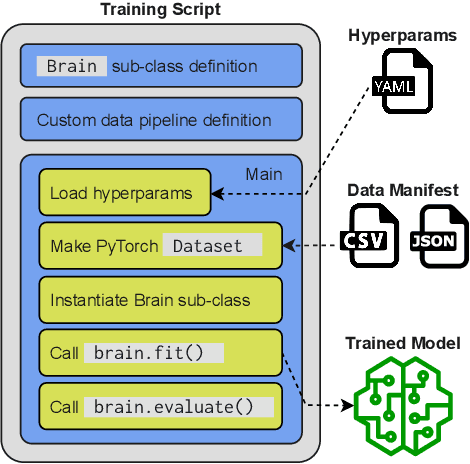

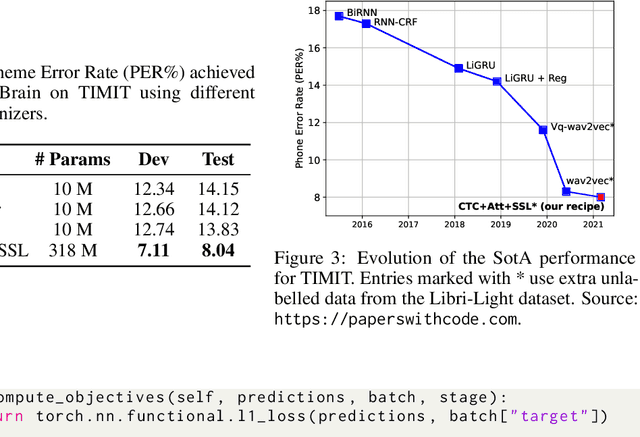
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to facilitate the research and development of neural speech processing technologies by being simple, flexible, user-friendly, and well-documented. This paper describes the core architecture designed to support several tasks of common interest, allowing users to naturally conceive, compare and share novel speech processing pipelines. SpeechBrain achieves competitive or state-of-the-art performance in a wide range of speech benchmarks. It also provides training recipes, pretrained models, and inference scripts for popular speech datasets, as well as tutorials which allow anyone with basic Python proficiency to familiarize themselves with speech technologies.
ECAPA-TDNN Embeddings for Speaker Diarization
Apr 03, 2021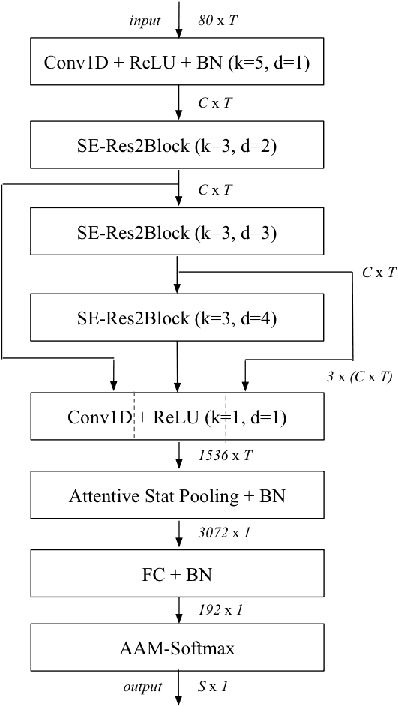
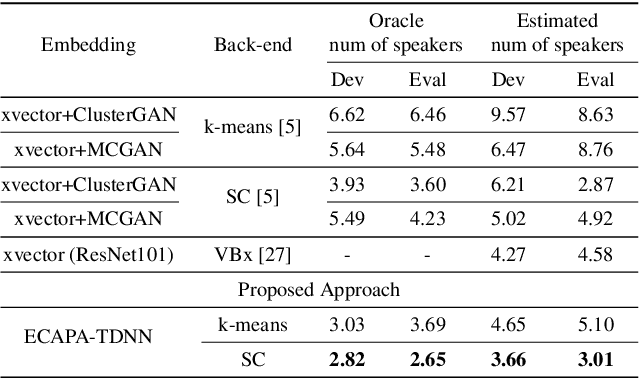
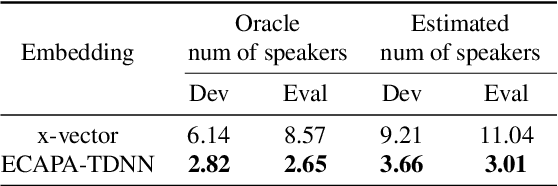
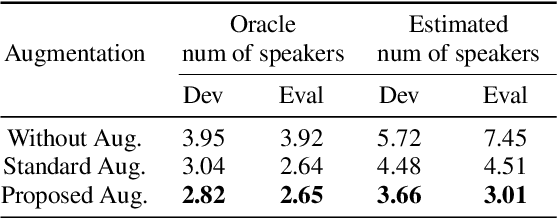
Learning robust speaker embeddings is a crucial step in speaker diarization. Deep neural networks can accurately capture speaker discriminative characteristics and popular deep embeddings such as x-vectors are nowadays a fundamental component of modern diarization systems. Recently, some improvements over the standard TDNN architecture used for x-vectors have been proposed. The ECAPA-TDNN model, for instance, has shown impressive performance in the speaker verification domain, thanks to a carefully designed neural model. In this work, we extend, for the first time, the use of the ECAPA-TDNN model to speaker diarization. Moreover, we improved its robustness with a powerful augmentation scheme that concatenates several contaminated versions of the same signal within the same training batch. The ECAPA-TDNN model turned out to provide robust speaker embeddings under both close-talking and distant-talking conditions. Our results on the popular AMI meeting corpus show that our system significantly outperforms recently proposed approaches.
Repurposing Pretrained Models for Robust Out-of-domain Few-Shot Learning
Mar 16, 2021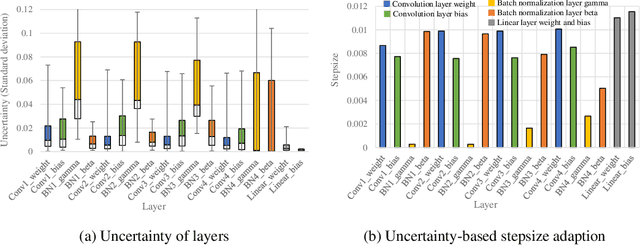
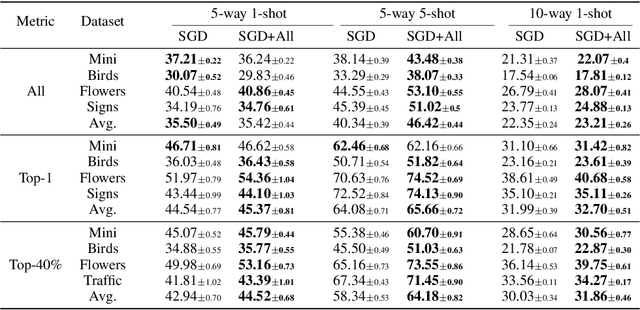
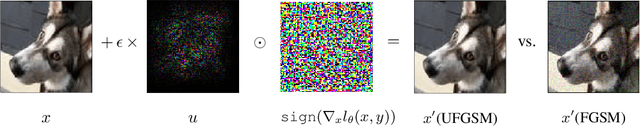
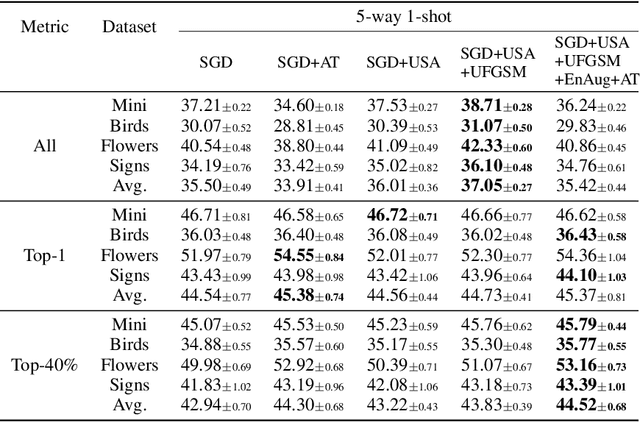
Model-agnostic meta-learning (MAML) is a popular method for few-shot learning but assumes that we have access to the meta-training set. In practice, training on the meta-training set may not always be an option due to data privacy concerns, intellectual property issues, or merely lack of computing resources. In this paper, we consider the novel problem of repurposing pretrained MAML checkpoints to solve new few-shot classification tasks. Because of the potential distribution mismatch, the original MAML steps may no longer be optimal. Therefore we propose an alternative meta-testing procedure and combine MAML gradient steps with adversarial training and uncertainty-based stepsize adaptation. Our method outperforms "vanilla" MAML on same-domain and cross-domains benchmarks using both SGD and Adam optimizers and shows improved robustness to the choice of base stepsize.