 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe IDLAB VoxCeleb Speaker Recognition Challenge 2021 System Description
Paper and Code
Sep 09, 2021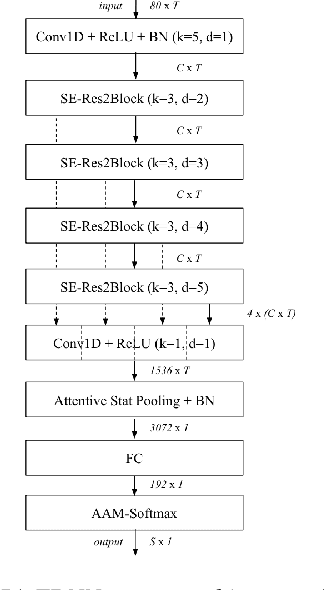
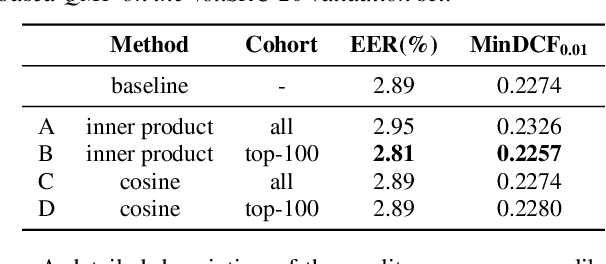
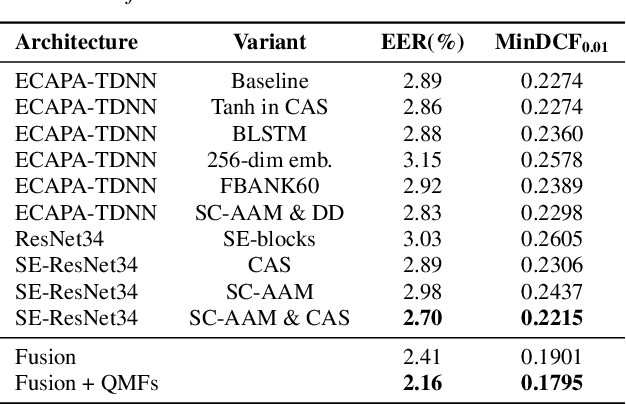
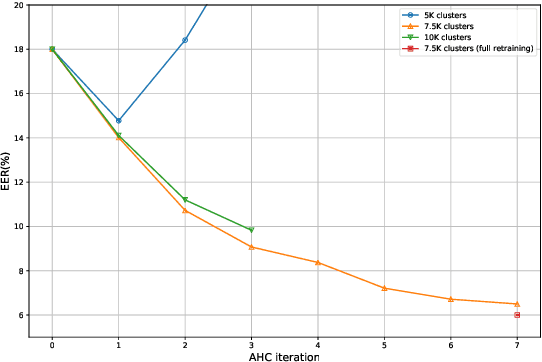
This technical report describes the IDLab submission for track 1 and 2 of the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC-21). This speaker verification competition focuses on short duration test recordings and cross-lingual trials. Currently, both Time Delay Neural Networks (TDNNs) and ResNets achieve state-of-the-art results in speaker verification. We opt to use a system fusion of hybrid architectures in our final submission. An ECAPA-TDNN baseline is enhanced with a 2D convolutional stem to transfer some of the strong characteristics of a ResNet based model to this hybrid CNN-TDNN architecture. Similarly, we incorporate absolute frequency positional information in the SE-ResNet architectures. All models are trained with a special mini-batch data sampling technique which constructs mini-batches with data that is the most challenging for the system on the level of intra-speaker variability. This intra-speaker variability is mainly caused by differences in language and background conditions between the speaker's utterances. The cross-lingual effects on the speaker verification scores are further compensated by introducing a binary cross-linguality trial feature in the logistic regression based system calibration. The final system fusion with two ECAPA CNN-TDNNs and three SE-ResNets enhanced with frequency positional information achieved a third place on the VoxSRC-21 leaderboard for both track 1 and 2 with a minDCF of 0.1291 and 0.1313 respectively.