 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Alignment Learning of Vision-Language Conceptual Systems
Paper and Code
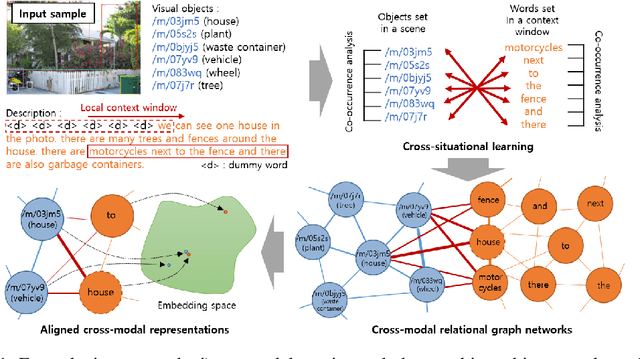

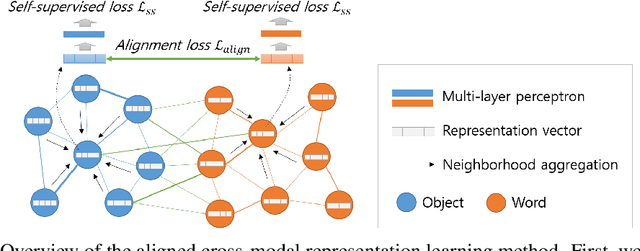

Human infants learn the names of objects and develop their own conceptual systems without explicit supervision. In this study, we propose methods for learning aligned vision-language conceptual systems inspired by infants' word learning mechanisms. The proposed model learns the associations of visual objects and words online and gradually constructs cross-modal relational graph networks. Additionally, we also propose an aligned cross-modal representation learning method that learns semantic representations of visual objects and words in a self-supervised manner based on the cross-modal relational graph networks. It allows entities of different modalities with conceptually the same meaning to have similar semantic representation vectors. We quantitatively and qualitatively evaluate our method, including object-to-word mapping and zero-shot learning tasks, showing that the proposed model significantly outperforms the baselines and that each conceptual system is topologically aligned.