 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess Gaussians, Texture More: 4K Feed-Forward Textured Splatting
Mar 26, 2026Existing feed-forward 3D Gaussian Splatting methods predict pixel-aligned primitives, leading to a quadratic growth in primitive count as resolution increases. This fundamentally limits their scalability, making high-resolution synthesis such as 4K intractable. We introduce LGTM (Less Gaussians, Texture More), a feed-forward framework that overcomes this resolution scaling barrier. By predicting compact Gaussian primitives coupled with per-primitive textures, LGTM decouples geometric complexity from rendering resolution. This approach enables high-fidelity 4K novel view synthesis without per-scene optimization, a capability previously out of reach for feed-forward methods, all while using significantly fewer Gaussian primitives. Project page: https://yxlao.github.io/lgtm/
Pixel-GS: Density Control with Pixel-aware Gradient for 3D Gaussian Splatting
Mar 22, 2024
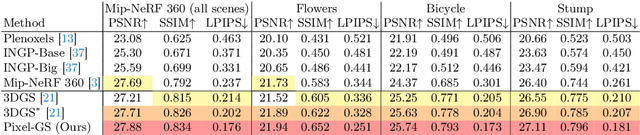
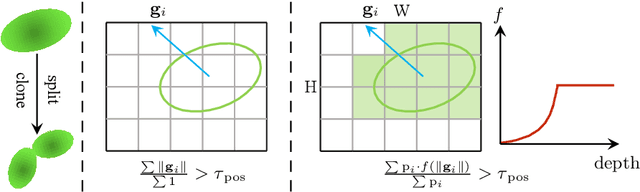

3D Gaussian Splatting (3DGS) has demonstrated impressive novel view synthesis results while advancing real-time rendering performance. However, it relies heavily on the quality of the initial point cloud, resulting in blurring and needle-like artifacts in areas with insufficient initializing points. This is mainly attributed to the point cloud growth condition in 3DGS that only considers the average gradient magnitude of points from observable views, thereby failing to grow for large Gaussians that are observable for many viewpoints while many of them are only covered in the boundaries. To this end, we propose a novel method, named Pixel-GS, to take into account the number of pixels covered by the Gaussian in each view during the computation of the growth condition. We regard the covered pixel numbers as the weights to dynamically average the gradients from different views, such that the growth of large Gaussians can be prompted. As a result, points within the areas with insufficient initializing points can be grown more effectively, leading to a more accurate and detailed reconstruction. In addition, we propose a simple yet effective strategy to scale the gradient field according to the distance to the camera, to suppress the growth of floaters near the camera. Extensive experiments both qualitatively and quantitatively demonstrate that our method achieves state-of-the-art rendering quality while maintaining real-time rendering speed, on the challenging Mip-NeRF 360 and Tanks & Temples datasets.
AlignMiF: Geometry-Aligned Multimodal Implicit Field for LiDAR-Camera Joint Synthesis
Feb 27, 2024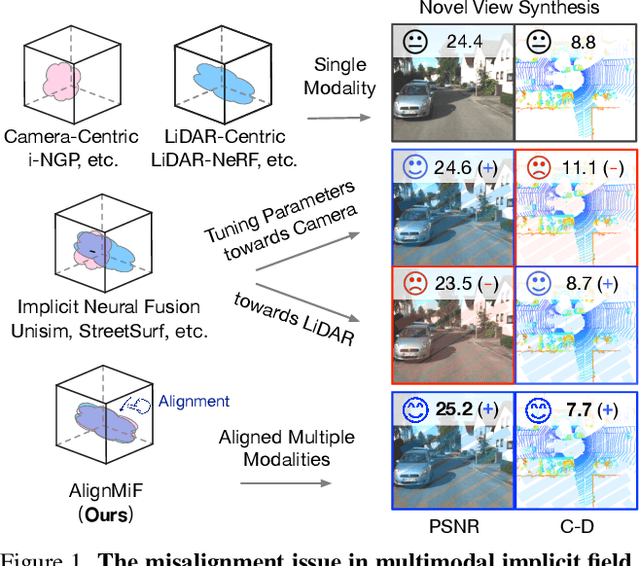
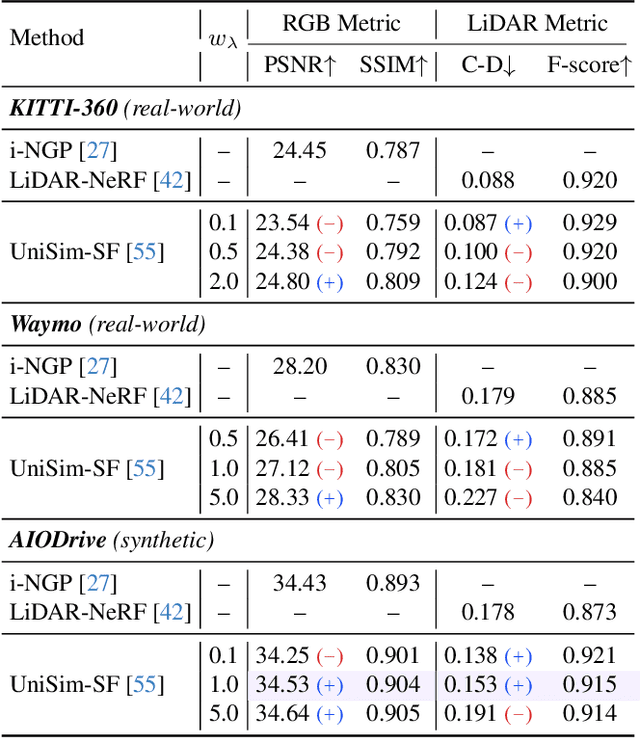

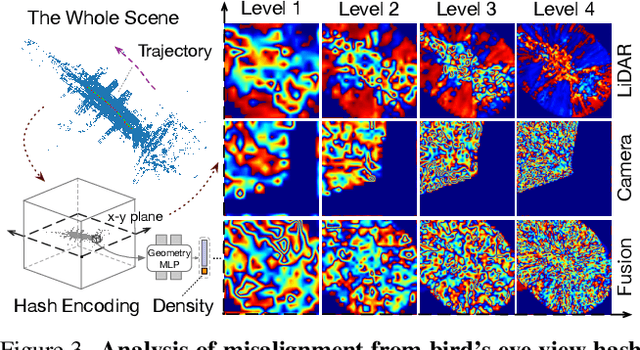
Neural implicit fields have been a de facto standard in novel view synthesis. Recently, there exist some methods exploring fusing multiple modalities within a single field, aiming to share implicit features from different modalities to enhance reconstruction performance. However, these modalities often exhibit misaligned behaviors: optimizing for one modality, such as LiDAR, can adversely affect another, like camera performance, and vice versa. In this work, we conduct comprehensive analyses on the multimodal implicit field of LiDAR-camera joint synthesis, revealing the underlying issue lies in the misalignment of different sensors. Furthermore, we introduce AlignMiF, a geometrically aligned multimodal implicit field with two proposed modules: Geometry-Aware Alignment (GAA) and Shared Geometry Initialization (SGI). These modules effectively align the coarse geometry across different modalities, significantly enhancing the fusion process between LiDAR and camera data. Through extensive experiments across various datasets and scenes, we demonstrate the effectiveness of our approach in facilitating better interaction between LiDAR and camera modalities within a unified neural field. Specifically, our proposed AlignMiF, achieves remarkable improvement over recent implicit fusion methods (+2.01 and +3.11 image PSNR on the KITTI-360 and Waymo datasets) and consistently surpasses single modality performance (13.8% and 14.2% reduction in LiDAR Chamfer Distance on the respective datasets).
Objects With Lighting: A Real-World Dataset for Evaluating Reconstruction and Rendering for Object Relighting
Jan 17, 2024



Reconstructing an object from photos and placing it virtually in a new environment goes beyond the standard novel view synthesis task as the appearance of the object has to not only adapt to the novel viewpoint but also to the new lighting conditions and yet evaluations of inverse rendering methods rely on novel view synthesis data or simplistic synthetic datasets for quantitative analysis. This work presents a real-world dataset for measuring the reconstruction and rendering of objects for relighting. To this end, we capture the environment lighting and ground truth images of the same objects in multiple environments allowing to reconstruct the objects from images taken in one environment and quantify the quality of the rendered views for the unseen lighting environments. Further, we introduce a simple baseline composed of off-the-shelf methods and test several state-of-the-art methods on the relighting task and show that novel view synthesis is not a reliable proxy to measure performance. Code and dataset are available at https://github.com/isl-org/objects-with-lighting .
CorresNeRF: Image Correspondence Priors for Neural Radiance Fields
Dec 11, 2023



Neural Radiance Fields (NeRFs) have achieved impressive results in novel view synthesis and surface reconstruction tasks. However, their performance suffers under challenging scenarios with sparse input views. We present CorresNeRF, a novel method that leverages image correspondence priors computed by off-the-shelf methods to supervise NeRF training. We design adaptive processes for augmentation and filtering to generate dense and high-quality correspondences. The correspondences are then used to regularize NeRF training via the correspondence pixel reprojection and depth loss terms. We evaluate our methods on novel view synthesis and surface reconstruction tasks with density-based and SDF-based NeRF models on different datasets. Our method outperforms previous methods in both photometric and geometric metrics. We show that this simple yet effective technique of using correspondence priors can be applied as a plug-and-play module across different NeRF variants. The project page is at https://yxlao.github.io/corres-nerf.
Point Transformer V2: Grouped Vector Attention and Partition-based Pooling
Oct 12, 2022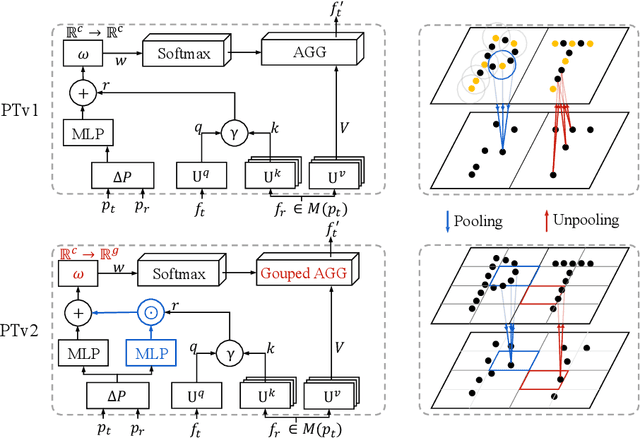
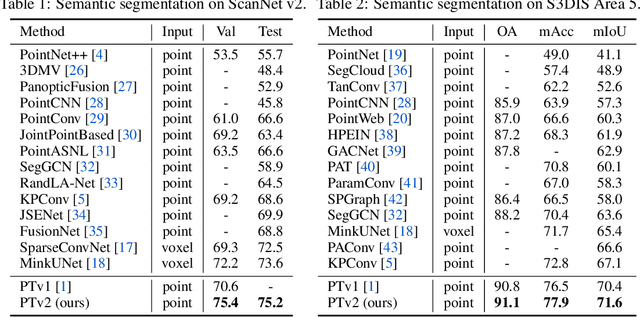

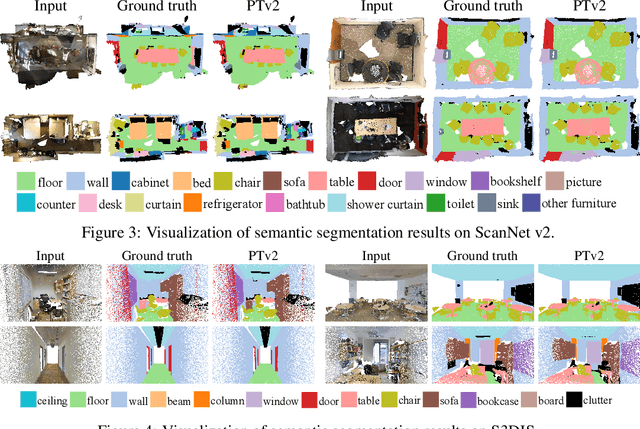
As a pioneering work exploring transformer architecture for 3D point cloud understanding, Point Transformer achieves impressive results on multiple highly competitive benchmarks. In this work, we analyze the limitations of the Point Transformer and propose our powerful and efficient Point Transformer V2 model with novel designs that overcome the limitations of previous work. In particular, we first propose group vector attention, which is more effective than the previous version of vector attention. Inheriting the advantages of both learnable weight encoding and multi-head attention, we present a highly effective implementation of grouped vector attention with a novel grouped weight encoding layer. We also strengthen the position information for attention by an additional position encoding multiplier. Furthermore, we design novel and lightweight partition-based pooling methods which enable better spatial alignment and more efficient sampling. Extensive experiments show that our model achieves better performance than its predecessor and achieves state-of-the-art on several challenging 3D point cloud understanding benchmarks, including 3D point cloud segmentation on ScanNet v2 and S3DIS and 3D point cloud classification on ModelNet40. Our code will be available at https://github.com/Gofinge/PointTransformerV2.
ASH: A Modern Framework for Parallel Spatial Hashing in 3D Perception
Oct 01, 2021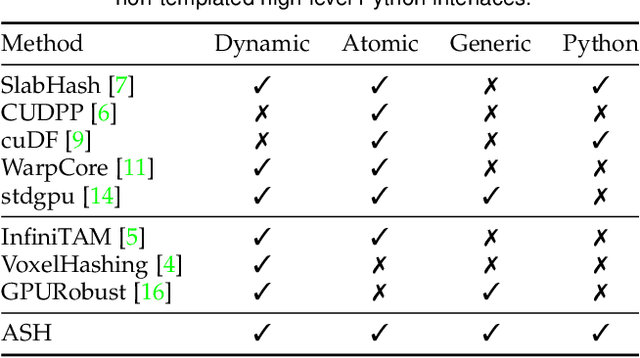
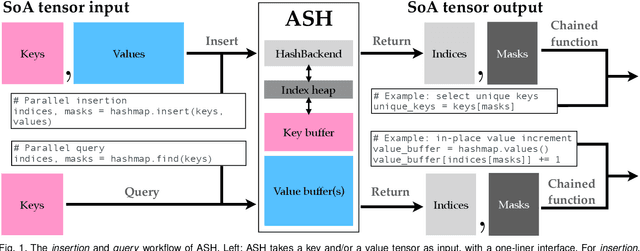
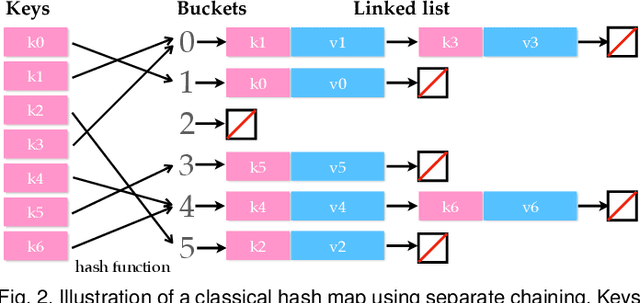

We present ASH, a modern and high-performance framework for parallel spatial hashing on GPU. Compared to existing GPU hash map implementations, ASH achieves higher performance, supports richer functionality, and requires fewer lines of code (LoC) when used for implementing spatially varying operations from volumetric geometry reconstruction to differentiable appearance reconstruction. Unlike existing GPU hash maps, the ASH framework provides a versatile tensor interface, hiding low-level details from the users. In addition, by decoupling the internal hashing data structures and key-value data in buffers, we offer direct access to spatially varying data via indices, enabling seamless integration to modern libraries such as PyTorch. To achieve this, we 1) detach stored key-value data from the low-level hash map implementation; 2) bridge the pointer-first low level data structures to index-first high-level tensor interfaces via an index heap; 3) adapt both generic and non-generic integer-only hash map implementations as backends to operate on multi-dimensional keys. We first profile our hash map against state-of-the-art hash maps on synthetic data to show the performance gain from this architecture. We then show that ASH can consistently achieve higher performance on various large-scale 3D perception tasks with fewer LoC by showcasing several applications, including 1) point cloud voxelization, 2) dense volumetric SLAM, 3) non-rigid point cloud registration and volumetric deformation, and 4) spatially varying geometry and appearance refinement. ASH and its example applications are open sourced in Open3D (http://www.open3d.org).
Intel nGraph: An Intermediate Representation, Compiler, and Executor for Deep Learning
Jan 30, 2018The Deep Learning (DL) community sees many novel topologies published each year. Achieving high performance on each new topology remains challenging, as each requires some level of manual effort. This issue is compounded by the proliferation of frameworks and hardware platforms. The current approach, which we call "direct optimization", requires deep changes within each framework to improve the training performance for each hardware backend (CPUs, GPUs, FPGAs, ASICs) and requires $\mathcal{O}(fp)$ effort; where $f$ is the number of frameworks and $p$ is the number of platforms. While optimized kernels for deep-learning primitives are provided via libraries like Intel Math Kernel Library for Deep Neural Networks (MKL-DNN), there are several compiler-inspired ways in which performance can be further optimized. Building on our experience creating neon (a fast deep learning library on GPUs), we developed Intel nGraph, a soon to be open-sourced C++ library to simplify the realization of optimized deep learning performance across frameworks and hardware platforms. Initially-supported frameworks include TensorFlow, MXNet, and Intel neon framework. Initial backends are Intel Architecture CPUs (CPU), the Intel(R) Nervana Neural Network Processor(R) (NNP), and NVIDIA GPUs. Currently supported compiler optimizations include efficient memory management and data layout abstraction. In this paper, we describe our overall architecture and its core components. In the future, we envision extending nGraph API support to a wider range of frameworks, hardware (including FPGAs and ASICs), and compiler optimizations (training versus inference optimizations, multi-node and multi-device scaling via efficient sub-graph partitioning, and HW-specific compounding of operations).