 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignMiF: Geometry-Aligned Multimodal Implicit Field for LiDAR-Camera Joint Synthesis
Paper and Code
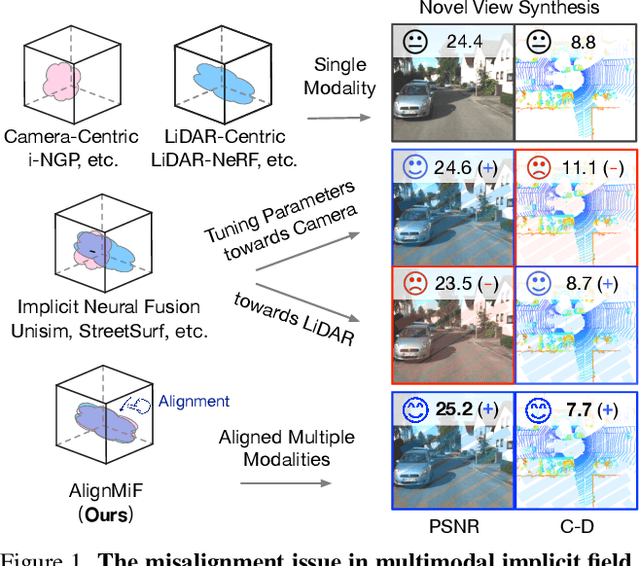
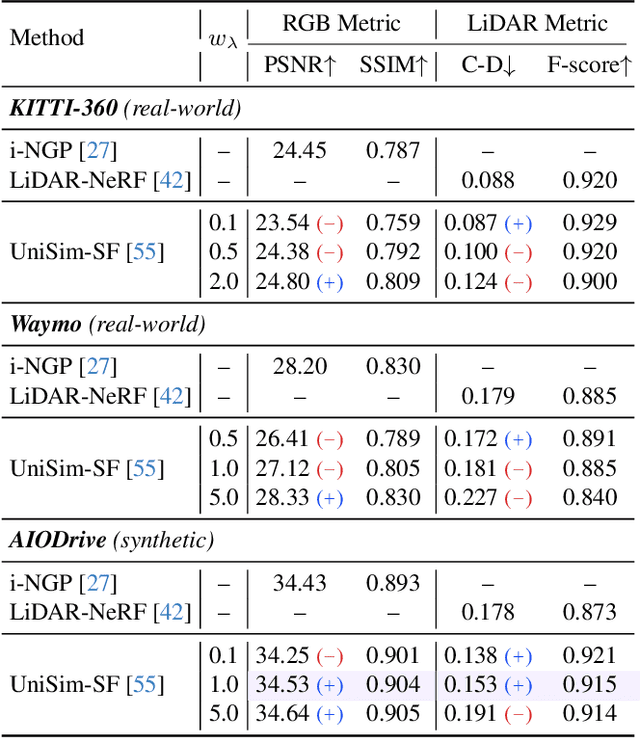

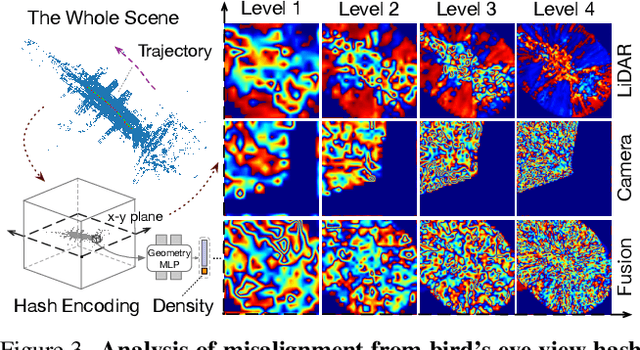
Neural implicit fields have been a de facto standard in novel view synthesis. Recently, there exist some methods exploring fusing multiple modalities within a single field, aiming to share implicit features from different modalities to enhance reconstruction performance. However, these modalities often exhibit misaligned behaviors: optimizing for one modality, such as LiDAR, can adversely affect another, like camera performance, and vice versa. In this work, we conduct comprehensive analyses on the multimodal implicit field of LiDAR-camera joint synthesis, revealing the underlying issue lies in the misalignment of different sensors. Furthermore, we introduce AlignMiF, a geometrically aligned multimodal implicit field with two proposed modules: Geometry-Aware Alignment (GAA) and Shared Geometry Initialization (SGI). These modules effectively align the coarse geometry across different modalities, significantly enhancing the fusion process between LiDAR and camera data. Through extensive experiments across various datasets and scenes, we demonstrate the effectiveness of our approach in facilitating better interaction between LiDAR and camera modalities within a unified neural field. Specifically, our proposed AlignMiF, achieves remarkable improvement over recent implicit fusion methods (+2.01 and +3.11 image PSNR on the KITTI-360 and Waymo datasets) and consistently surpasses single modality performance (13.8% and 14.2% reduction in LiDAR Chamfer Distance on the respective datasets).