 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Virtual to Real World Visual Perception using Domain Adaptation -- The DPM as Example
Paper and Code
Dec 29, 2016
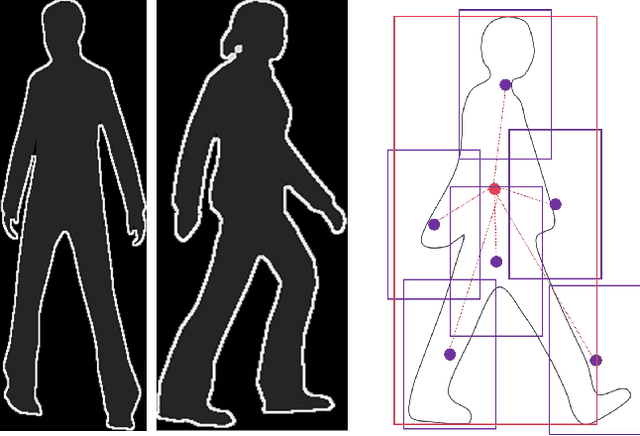
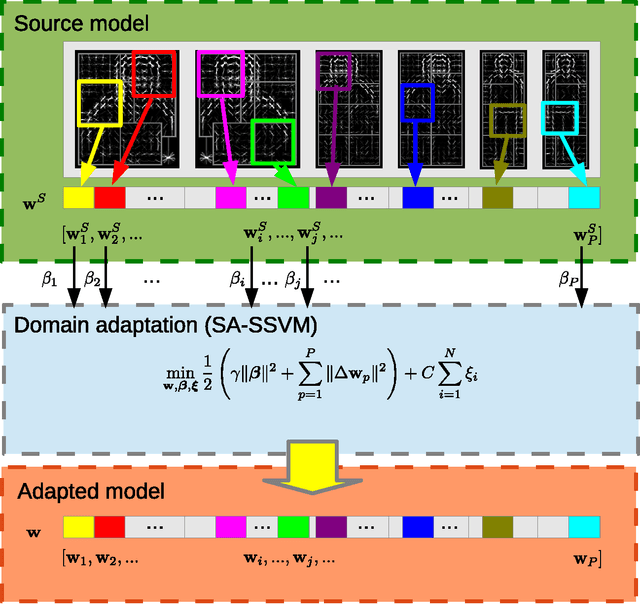

Supervised learning tends to produce more accurate classifiers than unsupervised learning in general. This implies that training data is preferred with annotations. When addressing visual perception challenges, such as localizing certain object classes within an image, the learning of the involved classifiers turns out to be a practical bottleneck. The reason is that, at least, we have to frame object examples with bounding boxes in thousands of images. A priori, the more complex the model is regarding its number of parameters, the more annotated examples are required. This annotation task is performed by human oracles, which ends up in inaccuracies and errors in the annotations (aka ground truth) since the task is inherently very cumbersome and sometimes ambiguous. As an alternative we have pioneered the use of virtual worlds for collecting such annotations automatically and with high precision. However, since the models learned with virtual data must operate in the real world, we still need to perform domain adaptation (DA). In this chapter we revisit the DA of a deformable part-based model (DPM) as an exemplifying case of virtual- to-real-world DA. As a use case, we address the challenge of vehicle detection for driver assistance, using different publicly available virtual-world data. While doing so, we investigate questions such as: how does the domain gap behave due to virtual-vs-real data with respect to dominant object appearance per domain, as well as the role of photo-realism in the virtual world.