 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical Representation-based Predicate Optimization for a Visual Analytics Database
Sep 10, 2018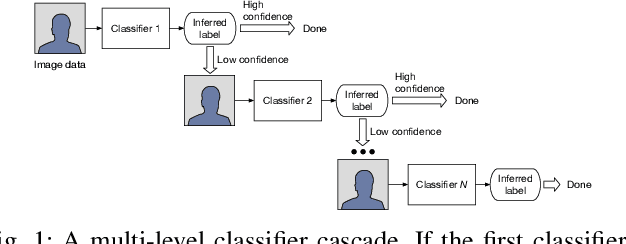

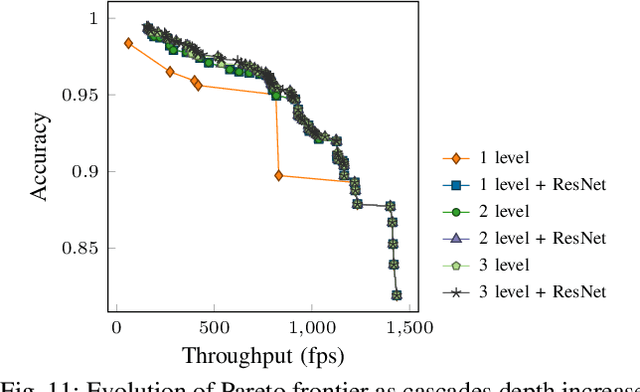
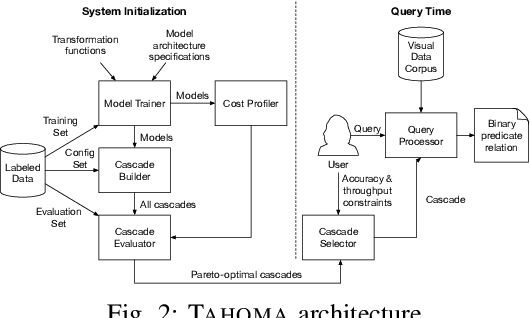
Querying the content of images, video, and other non-textual data sources requires expensive content extraction methods. Modern extraction techniques are based on deep convolutional neural networks (CNNs) and can classify objects within images with astounding accuracy. Unfortunately, these methods are slow: processing a single image can take about 10 milliseconds on modern GPU-based hardware. As massive video libraries become ubiquitous, running a content-based query over millions of video frames is prohibitive. One promising approach to reduce the runtime cost of queries of visual content is to use a hierarchical model, such as a cascade, where simple cases are handled by an inexpensive classifier. Prior work has sought to design cascades that optimize the computational cost of inference by, for example, using smaller CNNs. However, we observe that there are critical factors besides the inference time that dramatically impact the overall query time. Notably, by treating the physical representation of the input image as part of our query optimization---that is, by including image transforms, such as resolution scaling or color-depth reduction, within the cascade---we can optimize data handling costs and enable drastically more efficient classifier cascades. In this paper, we propose Tahoma, which generates and evaluates many potential classifier cascades that jointly optimize the CNN architecture and input data representation. Our experiments on a subset of ImageNet show that Tahoma's input transformations speed up cascades by up to 35 times. We also find up to a 98x speedup over the ResNet50 classifier with no loss in accuracy, and a 280x speedup if some accuracy is sacrificed.