 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Domain Adaptation for Computer Vision Tasks
Paper and Code
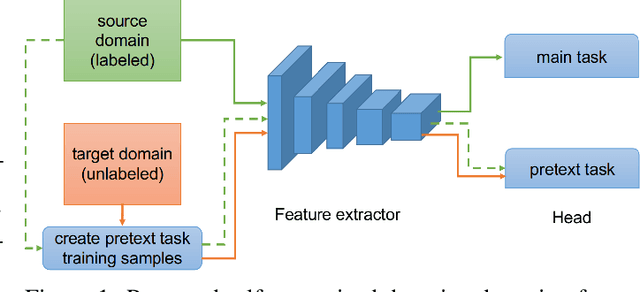
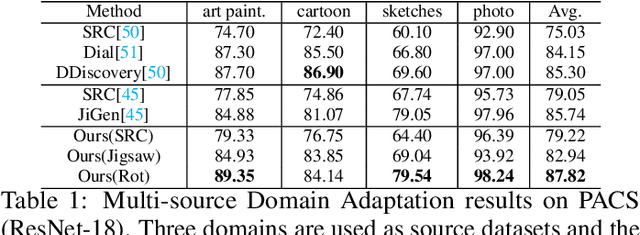

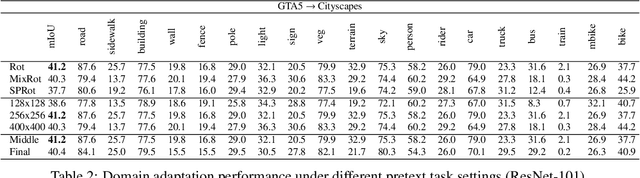
Recent progress of self-supervised visual representation learning has achieved remarkable success on many challenging computer vision benchmarks. However, whether these techniques can be used for domain adaptation has not been explored. In this work, we propose a generic method for self-supervised domain adaptation, using object recognition and semantic segmentation of urban scenes as use cases. Focusing on simple pretext/auxiliary tasks (e.g. image rotation prediction), we assess different learning strategies to improve domain adaptation effectiveness by self-supervision. Additionally, we propose two complementary strategies to further boost the domain adaptation accuracy within our method, consisting of prediction layer alignment and batch normalization calibration. For the experimental work, we focus on the relevant setting of training models using synthetic images, and adapting them to perform on real-world images. The obtained results show adaptation levels comparable to most studied domain adaptation methods, thus, bringing self-supervision as a new alternative for reaching domain adaptation. The code is available at https://github.com/Jiaolong/self-supervised-da.