 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Spiking Transformer Enabled By Partial Information
Paper and Code
Oct 03, 2022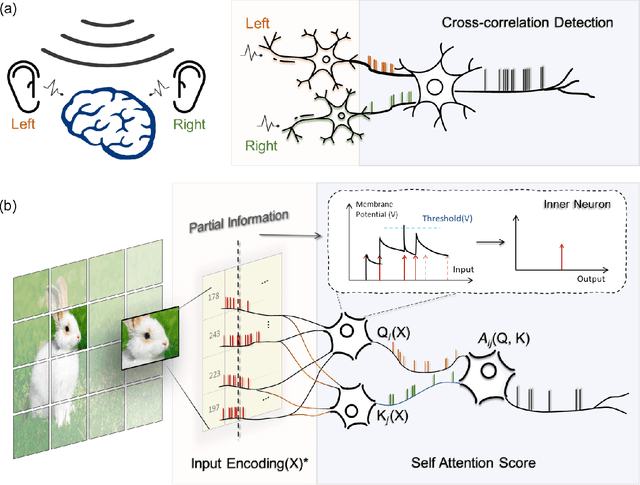



Spiking neural networks (SNNs) have received substantial attention in recent years due to their sparse and asynchronous communication nature, and thus can be deployed in neuromorphic hardware and achieve extremely high energy efficiency. However, SNNs currently can hardly realize a comparable performance to that of artificial neural networks (ANNs) because their limited scalability does not allow for large-scale networks. Especially for Transformer, as a model of ANNs that has accomplished remarkable performance in various machine learning tasks, its implementation in SNNs by conventional methods requires a large number of neurons, notably in the self-attention module. Inspired by the mechanisms in the nervous system, we propose an efficient spiking Transformer (EST) framework enabled by partial information to address the above problem. In this model, we not only implemented the self-attention module with a reasonable number of neurons, but also introduced partial-information self-attention (PSA), which utilizes only partial input signals, further reducing computational resources compared to conventional methods. The experimental results show that our EST can outperform the state-of-the-art SNN model in terms of accuracy and the number of time steps on both Cifar-10/100 and ImageNet datasets. In particular, the proposed EST model achieves 78.48% top-1 accuracy on the ImageNet dataset with only 16 time steps. In addition, our proposed PSA reduces flops by 49.8% with negligible performance loss compared to a self-attention module with full information.