 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDELT: A Simple Diversity-driven EarlyLate Training for Dataset Distillation
Nov 29, 2024Recent advances in dataset distillation have led to solutions in two main directions. The conventional batch-to-batch matching mechanism is ideal for small-scale datasets and includes bi-level optimization methods on models and syntheses, such as FRePo, RCIG, and RaT-BPTT, as well as other methods like distribution matching, gradient matching, and weight trajectory matching. Conversely, batch-to-global matching typifies decoupled methods, which are particularly advantageous for large-scale datasets. This approach has garnered substantial interest within the community, as seen in SRe$^2$L, G-VBSM, WMDD, and CDA. A primary challenge with the second approach is the lack of diversity among syntheses within each class since samples are optimized independently and the same global supervision signals are reused across different synthetic images. In this study, we propose a new Diversity-driven EarlyLate Training (DELT) scheme to enhance the diversity of images in batch-to-global matching with less computation. Our approach is conceptually simple yet effective, it partitions predefined IPC samples into smaller subtasks and employs local optimizations to distill each subset into distributions from distinct phases, reducing the uniformity induced by the unified optimization process. These distilled images from the subtasks demonstrate effective generalization when applied to the entire task. We conduct extensive experiments on CIFAR, Tiny-ImageNet, ImageNet-1K, and its sub-datasets. Our approach outperforms the previous state-of-the-art by 2$\sim$5% on average across different datasets and IPCs (images per class), increasing diversity per class by more than 5% while reducing synthesis time by up to 39.3% for enhancing the training efficiency. Code is available at: https://github.com/VILA-Lab/DELT.
Self-supervised Dataset Distillation: A Good Compression Is All You Need
Apr 11, 2024



Dataset distillation aims to compress information from a large-scale original dataset to a new compact dataset while striving to preserve the utmost degree of the original data informational essence. Previous studies have predominantly concentrated on aligning the intermediate statistics between the original and distilled data, such as weight trajectory, features, gradient, BatchNorm, etc. In this work, we consider addressing this task through the new lens of model informativeness in the compression stage on the original dataset pretraining. We observe that with the prior state-of-the-art SRe$^2$L, as model sizes increase, it becomes increasingly challenging for supervised pretrained models to recover learned information during data synthesis, as the channel-wise mean and variance inside the model are flatting and less informative. We further notice that larger variances in BN statistics from self-supervised models enable larger loss signals to update the recovered data by gradients, enjoying more informativeness during synthesis. Building on this observation, we introduce SC-DD, a simple yet effective Self-supervised Compression framework for Dataset Distillation that facilitates diverse information compression and recovery compared to traditional supervised learning schemes, further reaps the potential of large pretrained models with enhanced capabilities. Extensive experiments are conducted on CIFAR-100, Tiny-ImageNet and ImageNet-1K datasets to demonstrate the superiority of our proposed approach. The proposed SC-DD outperforms all previous state-of-the-art supervised dataset distillation methods when employing larger models, such as SRe$^2$L, MTT, TESLA, DC, CAFE, etc., by large margins under the same recovery and post-training budgets. Code is available at https://github.com/VILA-Lab/SRe2L/tree/main/SCDD/.
Dataset Distillation in Large Data Era
Nov 30, 2023Dataset distillation aims to generate a smaller but representative subset from a large dataset, which allows a model to be trained efficiently, meanwhile evaluating on the original testing data distribution to achieve decent performance. Many prior works have aimed to align with diverse aspects of the original datasets, such as matching the training weight trajectories, gradient, feature/BatchNorm distributions, etc. In this work, we show how to distill various large-scale datasets such as full ImageNet-1K/21K under a conventional input resolution of 224$\times$224 to achieve the best accuracy over all previous approaches, including SRe$^2$L, TESLA and MTT. To achieve this, we introduce a simple yet effective ${\bf C}$urriculum ${\bf D}$ata ${\bf A}$ugmentation ($\texttt{CDA}$) during data synthesis that obtains the accuracy on large-scale ImageNet-1K and 21K with 63.2% under IPC (Images Per Class) 50 and 36.1% under IPC 20, respectively. Finally, we show that, by integrating all our enhancements together, the proposed model beats the current state-of-the-art by more than 4% Top-1 accuracy on ImageNet-1K/21K and for the first time, reduces the gap to its full-data training counterpart to less than absolute 15%. Moreover, this work represents the inaugural success in dataset distillation on larger-scale ImageNet-21K under the standard 224$\times$224 resolution. Our code and distilled ImageNet-21K dataset of 20 IPC, 2K recovery budget are available at https://github.com/VILA-Lab/SRe2L/tree/main/CDA.
Generalized Large-Scale Data Condensation via Various Backbone and Statistical Matching
Nov 29, 2023



The lightweight "local-match-global" matching introduced by SRe2L successfully creates a distilled dataset with comprehensive information on the full 224x224 ImageNet-1k. However, this one-sided approach is limited to a particular backbone, layer, and statistics, which limits the improvement of the generalization of a distilled dataset. We suggest that sufficient and various "local-match-global" matching are more precise and effective than a single one and has the ability to create a distilled dataset with richer information and better generalization. We call this perspective "generalized matching" and propose Generalized Various Backbone and Statistical Matching (G-VBSM) in this work, which aims to create a synthetic dataset with densities, ensuring consistency with the complete dataset across various backbones, layers, and statistics. As experimentally demonstrated, G-VBSM is the first algorithm to obtain strong performance across both small-scale and large-scale datasets. Specifically, G-VBSM achieves a performance of 38.7% on CIFAR-100 with 128-width ConvNet, 47.6% on Tiny-ImageNet with ResNet18, and 31.4% on the full 224x224 ImageNet-1k with ResNet18, under images per class (IPC) 10, 50, and 10, respectively. These results surpass all SOTA methods by margins of 3.9%, 6.5%, and 10.1%, respectively.
Rethinking Mixup for Improving the Adversarial Transferability
Nov 28, 2023Mixup augmentation has been widely integrated to generate adversarial examples with superior adversarial transferability when immigrating from a surrogate model to other models. However, the underlying mechanism influencing the mixup's effect on transferability remains unexplored. In this work, we posit that the adversarial examples located at the convergence of decision boundaries across various categories exhibit better transferability and identify that Admix tends to steer the adversarial examples towards such regions. However, we find the constraint on the added image in Admix decays its capability, resulting in limited transferability. To address such an issue, we propose a new input transformation-based attack called Mixing the Image but Separating the gradienT (MIST). Specifically, MIST randomly mixes the input image with a randomly shifted image and separates the gradient of each loss item for each mixed image. To counteract the imprecise gradient, MIST calculates the gradient on several mixed images for each input sample. Extensive experimental results on the ImageNet dataset demonstrate that MIST outperforms existing SOTA input transformation-based attacks with a clear margin on both Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) w/wo defense mechanisms, supporting MIST's high effectiveness and generality.
Squeeze, Recover and Relabel: Dataset Condensation at ImageNet Scale From A New Perspective
Jun 22, 2023We present a new dataset condensation framework termed Squeeze, Recover and Relabel (SRe$^2$L) that decouples the bilevel optimization of model and synthetic data during training, to handle varying scales of datasets, model architectures and image resolutions for effective dataset condensation. The proposed method demonstrates flexibility across diverse dataset scales and exhibits multiple advantages in terms of arbitrary resolutions of synthesized images, low training cost and memory consumption with high-resolution training, and the ability to scale up to arbitrary evaluation network architectures. Extensive experiments are conducted on Tiny-ImageNet and full ImageNet-1K datasets. Under 50 IPC, our approach achieves the highest 42.5% and 60.8% validation accuracy on Tiny-ImageNet and ImageNet-1K, outperforming all previous state-of-the-art methods by margins of 14.5% and 32.9%, respectively. Our approach also outperforms MTT by approximately 52$\times$ (ConvNet-4) and 16$\times$ (ResNet-18) faster in speed with less memory consumption of 11.6$\times$ and 6.4$\times$ during data synthesis. Our code and condensed datasets of 50, 200 IPC with 4K recovery budget are available at https://zeyuanyin.github.io/projects/SRe2L/.
Backdoor Attacks on Federated Learning with Lottery Ticket Hypothesis
Sep 22, 2021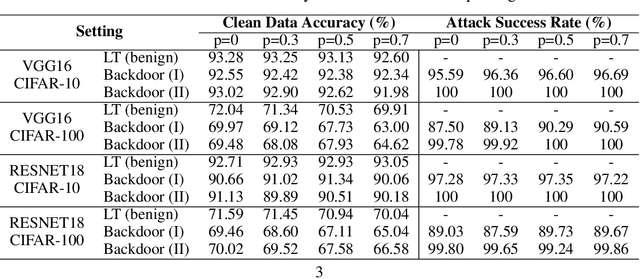
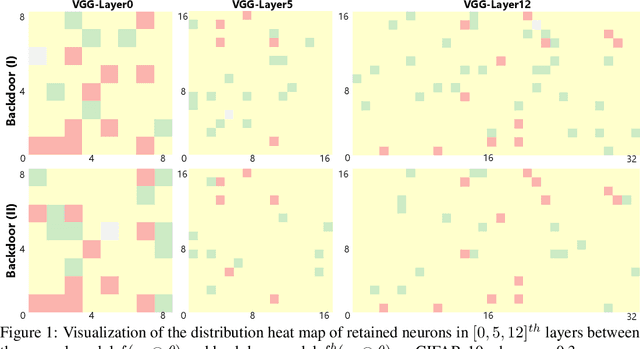
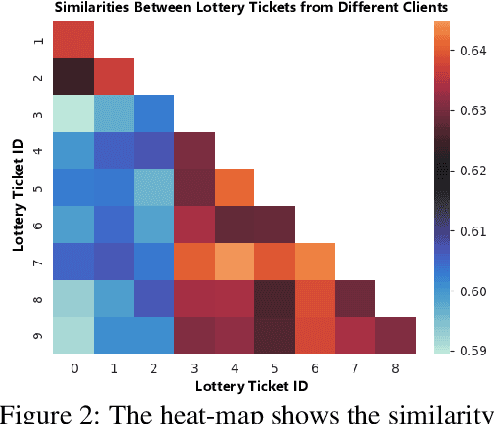

Edge devices in federated learning usually have much more limited computation and communication resources compared to servers in a data center. Recently, advanced model compression methods, like the Lottery Ticket Hypothesis, have already been implemented on federated learning to reduce the model size and communication cost. However, Backdoor Attack can compromise its implementation in the federated learning scenario. The malicious edge device trains the client model with poisoned private data and uploads parameters to the center, embedding a backdoor to the global shared model after unwitting aggregative optimization. During the inference phase, the model with backdoors classifies samples with a certain trigger as one target category, while shows a slight decrease in inference accuracy to clean samples. In this work, we empirically demonstrate that Lottery Ticket models are equally vulnerable to backdoor attacks as the original dense models, and backdoor attacks can influence the structure of extracted tickets. Based on tickets' similarities between each other, we provide a feasible defense for federated learning against backdoor attacks on various datasets.