 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Dynamic Spectrum Access via Fully Decentralized Multi-Agent Reinforcement Learning
Paper and Code
Mar 31, 2025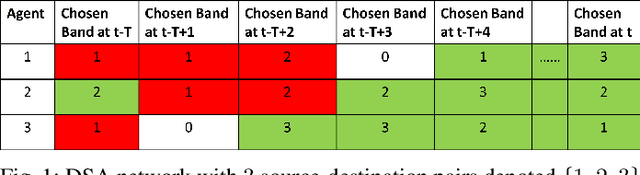
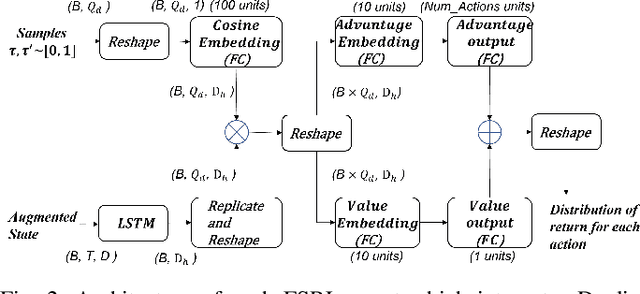
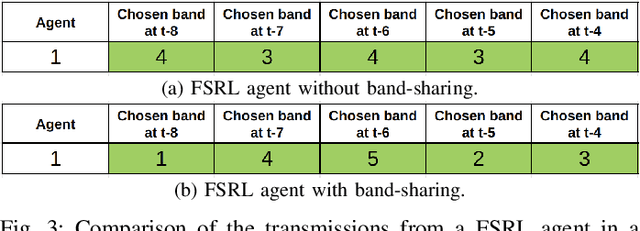
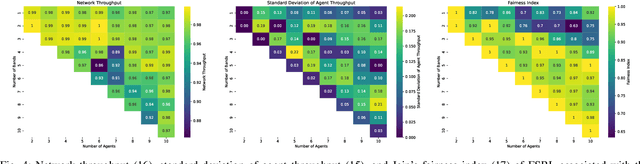
We consider a decentralized wireless network with several source-destination pairs sharing a limited number of orthogonal frequency bands. Sources learn to adapt their transmissions (specifically, their band selection strategy) over time, in a decentralized manner, without sharing information with each other. Sources can only observe the outcome of their own transmissions (i.e., success or collision), having no prior knowledge of the network size or of the transmission strategy of other sources. The goal of each source is to maximize their own throughput while striving for network-wide fairness. We propose a novel fully decentralized Reinforcement Learning (RL)-based solution that achieves fairness without coordination. The proposed Fair Share RL (FSRL) solution combines: (i) state augmentation with a semi-adaptive time reference; (ii) an architecture that leverages risk control and time difference likelihood; and (iii) a fairness-driven reward structure. We evaluate FSRL in more than 50 network settings with different number of agents, different amounts of available spectrum, in the presence of jammers, and in an ad-hoc setting. Simulation results suggest that, when we compare FSRL with a common baseline RL algorithm from the literature, FSRL can be up to 89.0% fairer (as measured by Jain's fairness index) in stringent settings with several sources and a single frequency band, and 48.1% fairer on average.