 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Native 6G Physical Layer with Cross-Module Optimization and Cooperative Control Agents
Jan 07, 2026In this article, a framework of AI-native cross-module optimized physical layer with cooperative control agents is proposed, which involves optimization across global AI/ML modules of the physical layer with innovative design of multiple enhancement mechanisms and control strategies. Specifically, it achieves simultaneous optimization across global modules of uplink AI/ML-based joint source-channel coding with modulation, and downlink AI/ML-based modulation with precoding and corresponding data detection, reducing traditional inter-module information barriers to facilitate end-to-end optimization toward global objectives. Moreover, multiple enhancement mechanisms are also proposed, including i) an AI/ML-based cross-layer modulation approach with theoretical analysis for downlink transmission that breaks the isolation of inter-layer features to expand the solution space for determining improved constellation, ii) a utility-oriented precoder construction method that shifts the role of the AI/ML-based CSI feedback decoder from recovering the original CSI to directly generating precoding matrices aiming to improve end-to-end performance, and iii) incorporating modulation into AI/ML-based CSI feedback to bypass bit-level bottlenecks that introduce quantization errors, non-differentiable gradients, and limitations in constellation solution spaces. Furthermore, AI/ML based control agents for optimized transmission schemes are proposed that leverage AI/ML to perform model switching according to channel state, thereby enabling integrated control for global throughput optimization. Finally, simulation results demonstrate the superiority of the proposed solutions in terms of BLER and throughput. These extensive simulations employ more practical assumptions that are aligned with the requirements of the 3GPP, which hopefully provides valuable insights for future standardization discussions.
Exploring Gradient-Guided Masked Language Model to Detect Textual Adversarial Attacks
Apr 08, 2025Textual adversarial examples pose serious threats to the reliability of natural language processing systems. Recent studies suggest that adversarial examples tend to deviate from the underlying manifold of normal texts, whereas pre-trained masked language models can approximate the manifold of normal data. These findings inspire the exploration of masked language models for detecting textual adversarial attacks. We first introduce Masked Language Model-based Detection (MLMD), leveraging the mask and unmask operations of the masked language modeling (MLM) objective to induce the difference in manifold changes between normal and adversarial texts. Although MLMD achieves competitive detection performance, its exhaustive one-by-one masking strategy introduces significant computational overhead. Our posterior analysis reveals that a significant number of non-keywords in the input are not important for detection but consume resources. Building on this, we introduce Gradient-guided MLMD (GradMLMD), which leverages gradient information to identify and skip non-keywords during detection, significantly reducing resource consumption without compromising detection performance.
Masked Language Model Based Textual Adversarial Example Detection
Apr 19, 2023
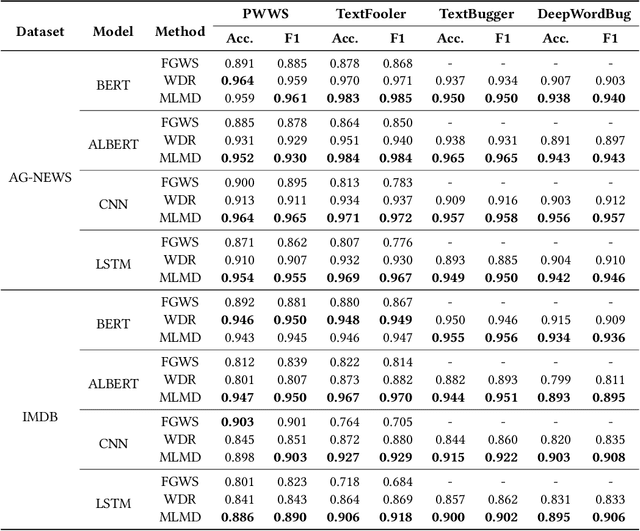


Adversarial attacks are a serious threat to the reliable deployment of machine learning models in safety-critical applications. They can misguide current models to predict incorrectly by slightly modifying the inputs. Recently, substantial work has shown that adversarial examples tend to deviate from the underlying data manifold of normal examples, whereas pre-trained masked language models can fit the manifold of normal NLP data. To explore how to use the masked language model in adversarial detection, we propose a novel textual adversarial example detection method, namely Masked Language Model-based Detection (MLMD), which can produce clearly distinguishable signals between normal examples and adversarial examples by exploring the changes in manifolds induced by the masked language model. MLMD features a plug and play usage (i.e., no need to retrain the victim model) for adversarial defense and it is agnostic to classification tasks, victim model's architectures, and to-be-defended attack methods. We evaluate MLMD on various benchmark textual datasets, widely studied machine learning models, and state-of-the-art (SOTA) adversarial attacks (in total $3*4*4 = 48$ settings). Experimental results show that MLMD can achieve strong performance, with detection accuracy up to 0.984, 0.967, and 0.901 on AG-NEWS, IMDB, and SST-2 datasets, respectively. Additionally, MLMD is superior, or at least comparable to, the SOTA detection defenses in detection accuracy and F1 score. Among many defenses based on the off-manifold assumption of adversarial examples, this work offers a new angle for capturing the manifold change. The code for this work is openly accessible at \url{https://github.com/mlmddetection/MLMDdetection}.
Evaluating Membership Inference Through Adversarial Robustness
May 14, 2022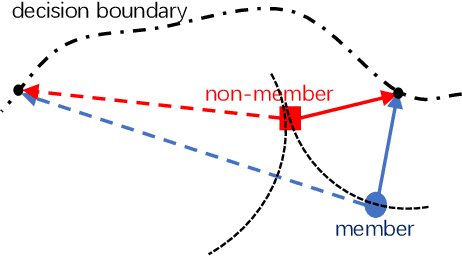
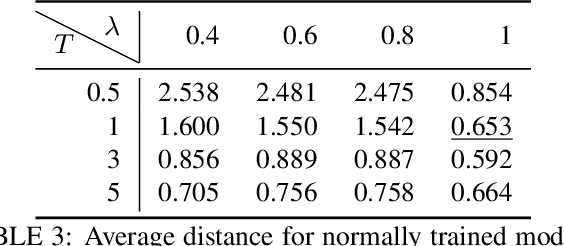
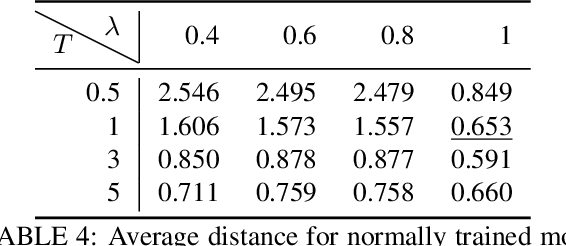
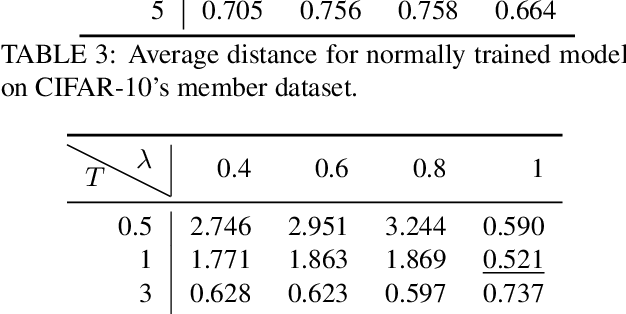
The usage of deep learning is being escalated in many applications. Due to its outstanding performance, it is being used in a variety of security and privacy-sensitive areas in addition to conventional applications. One of the key aspects of deep learning efficacy is to have abundant data. This trait leads to the usage of data which can be highly sensitive and private, which in turn causes wariness with regard to deep learning in the general public. Membership inference attacks are considered lethal as they can be used to figure out whether a piece of data belongs to the training dataset or not. This can be problematic with regards to leakage of training data information and its characteristics. To highlight the significance of these types of attacks, we propose an enhanced methodology for membership inference attacks based on adversarial robustness, by adjusting the directions of adversarial perturbations through label smoothing under a white-box setting. We evaluate our proposed method on three datasets: Fashion-MNIST, CIFAR-10, and CIFAR-100. Our experimental results reveal that the performance of our method surpasses that of the existing adversarial robustness-based method when attacking normally trained models. Additionally, through comparing our technique with the state-of-the-art metric-based membership inference methods, our proposed method also shows better performance when attacking adversarially trained models. The code for reproducing the results of this work is available at \url{https://github.com/plll4zzx/Evaluating-Membership-Inference-Through-Adversarial-Robustness}.
Self-Supervised Adversarial Example Detection by Disentangled Representation
May 27, 2021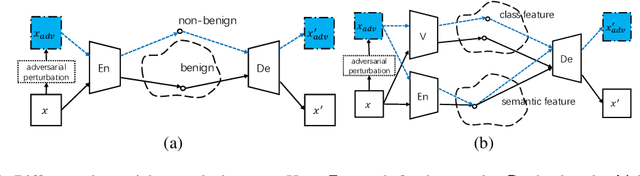
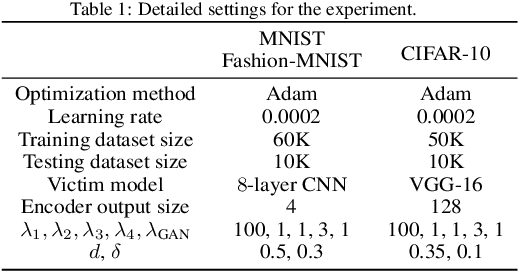
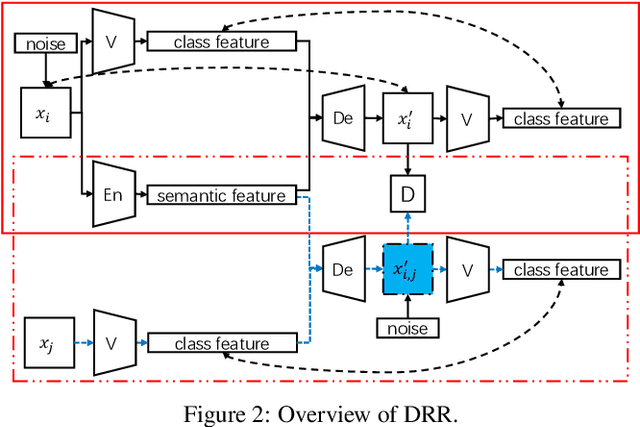
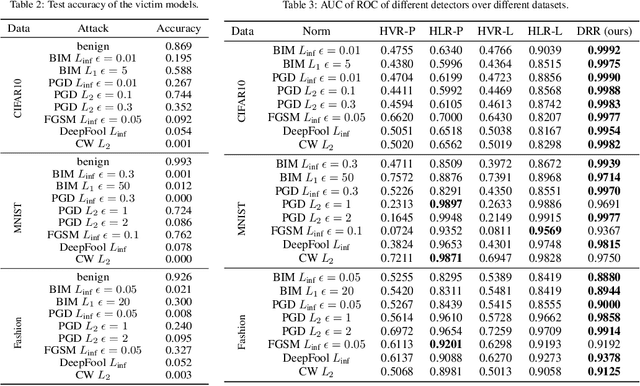
Deep learning models are known to be vulnerable to adversarial examples that are elaborately designed for malicious purposes and are imperceptible to the human perceptual system. Autoencoder, when trained solely over benign examples, has been widely used for (self-supervised) adversarial detection based on the assumption that adversarial examples yield larger reconstruction error. However, because lacking adversarial examples in its training and the too strong generalization ability of autoencoder, this assumption does not always hold true in practice. To alleviate this problem, we explore to detect adversarial examples by disentangled representations of images under the autoencoder structure. By disentangling input images as class features and semantic features, we train an autoencoder, assisted by a discriminator network, over both correctly paired class/semantic features and incorrectly paired class/semantic features to reconstruct benign and counterexamples. This mimics the behavior of adversarial examples and can reduce the unnecessary generalization ability of autoencoder. Compared with the state-of-the-art self-supervised detection methods, our method exhibits better performance in various measurements (i.e., AUC, FPR, TPR) over different datasets (MNIST, Fashion-MNIST and CIFAR-10), different adversarial attack methods (FGSM, BIM, PGD, DeepFool, and CW) and different victim models (8-layer CNN and 16-layer VGG). We compare our method with the state-of-the-art self-supervised detection methods under different adversarial attacks and different victim models (30 attack settings), and it exhibits better performance in various measurements (AUC, FPR, TPR) for most attacks settings. Ideally, AUC is $1$ and our method achieves $0.99+$ on CIFAR-10 for all attacks. Notably, different from other Autoencoder-based detectors, our method can provide resistance to the adaptive adversary.