 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Adversarial Example Detection by Disentangled Representation
Paper and Code
May 27, 2021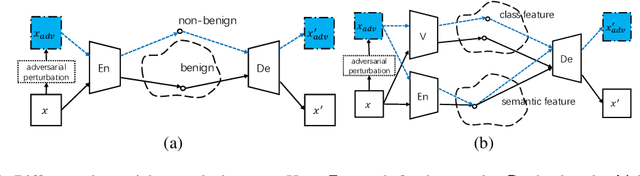
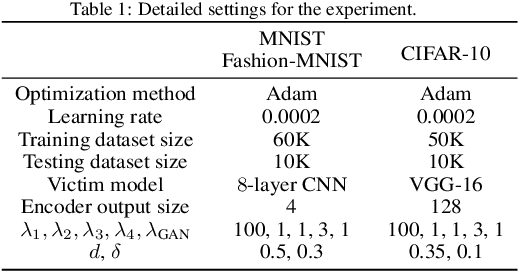
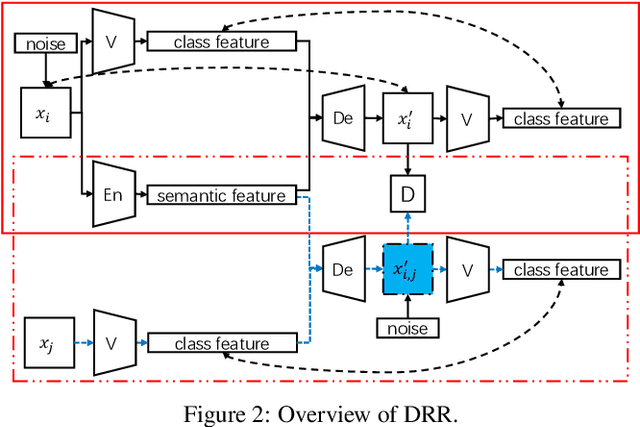
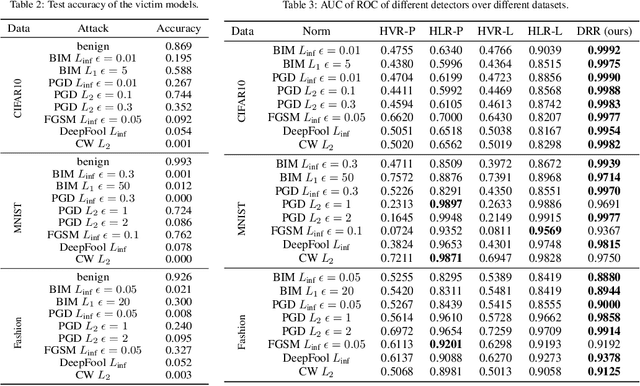
Deep learning models are known to be vulnerable to adversarial examples that are elaborately designed for malicious purposes and are imperceptible to the human perceptual system. Autoencoder, when trained solely over benign examples, has been widely used for (self-supervised) adversarial detection based on the assumption that adversarial examples yield larger reconstruction error. However, because lacking adversarial examples in its training and the too strong generalization ability of autoencoder, this assumption does not always hold true in practice. To alleviate this problem, we explore to detect adversarial examples by disentangled representations of images under the autoencoder structure. By disentangling input images as class features and semantic features, we train an autoencoder, assisted by a discriminator network, over both correctly paired class/semantic features and incorrectly paired class/semantic features to reconstruct benign and counterexamples. This mimics the behavior of adversarial examples and can reduce the unnecessary generalization ability of autoencoder. Compared with the state-of-the-art self-supervised detection methods, our method exhibits better performance in various measurements (i.e., AUC, FPR, TPR) over different datasets (MNIST, Fashion-MNIST and CIFAR-10), different adversarial attack methods (FGSM, BIM, PGD, DeepFool, and CW) and different victim models (8-layer CNN and 16-layer VGG). We compare our method with the state-of-the-art self-supervised detection methods under different adversarial attacks and different victim models (30 attack settings), and it exhibits better performance in various measurements (AUC, FPR, TPR) for most attacks settings. Ideally, AUC is $1$ and our method achieves $0.99+$ on CIFAR-10 for all attacks. Notably, different from other Autoencoder-based detectors, our method can provide resistance to the adaptive adversary.