 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Adaptive Dexterous Grasping from Single Demonstrations
Mar 26, 2025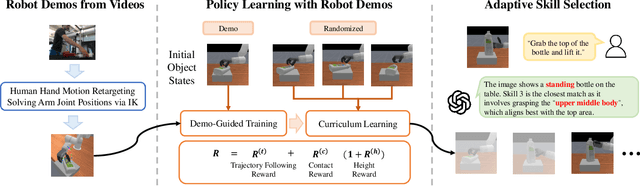

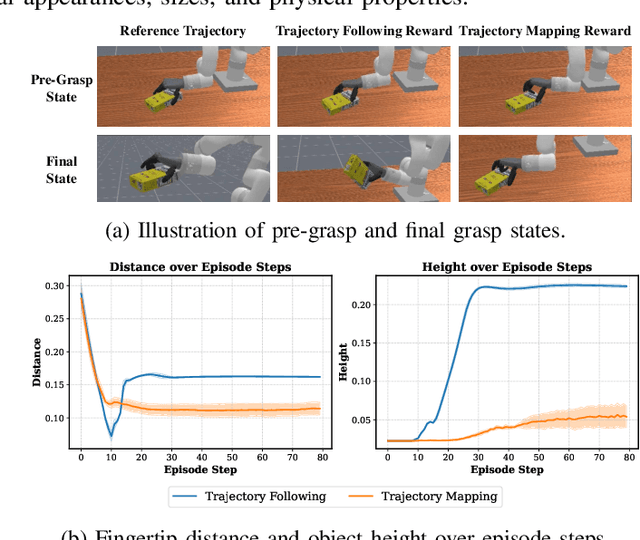
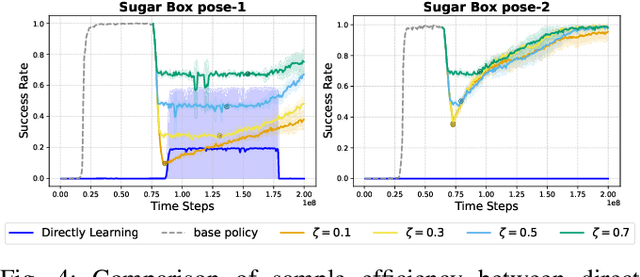
How can robots learn dexterous grasping skills efficiently and apply them adaptively based on user instructions? This work tackles two key challenges: efficient skill acquisition from limited human demonstrations and context-driven skill selection. We introduce AdaDexGrasp, a framework that learns a library of grasping skills from a single human demonstration per skill and selects the most suitable one using a vision-language model (VLM). To improve sample efficiency, we propose a trajectory following reward that guides reinforcement learning (RL) toward states close to a human demonstration while allowing flexibility in exploration. To learn beyond the single demonstration, we employ curriculum learning, progressively increasing object pose variations to enhance robustness. At deployment, a VLM retrieves the appropriate skill based on user instructions, bridging low-level learned skills with high-level intent. We evaluate AdaDexGrasp in both simulation and real-world settings, showing that our approach significantly improves RL efficiency and enables learning human-like grasp strategies across varied object configurations. Finally, we demonstrate zero-shot transfer of our learned policies to a real-world PSYONIC Ability Hand, with a 90% success rate across objects, significantly outperforming the baseline.
EasyHeC++: Fully Automatic Hand-Eye Calibration with Pretrained Image Models
Oct 11, 2024



Hand-eye calibration plays a fundamental role in robotics by directly influencing the efficiency of critical operations such as manipulation and grasping. In this work, we present a novel framework, EasyHeC++, designed for fully automatic hand-eye calibration. In contrast to previous methods that necessitate manual calibration, specialized markers, or the training of arm-specific neural networks, our approach is the first system that enables accurate calibration of any robot arm in a marker-free, training-free, and fully automatic manner. Our approach employs a two-step process. First, we initialize the camera pose using a sampling or feature-matching-based method with the aid of pretrained image models. Subsequently, we perform pose optimization through differentiable rendering. Extensive experiments demonstrate the system's superior accuracy in both synthetic and real-world datasets across various robot arms and camera settings. Project page: https://ootts.github.io/easyhec_plus.