 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Cross-domain Graph Learning: Progress and Future Directions
Mar 14, 2025
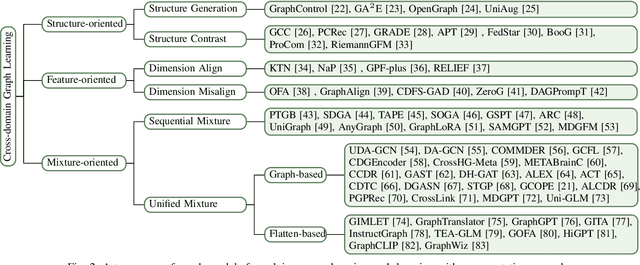


Graph learning plays a vital role in mining and analyzing complex relationships involved in graph data, which is widely used in many real-world applications like transaction networks and communication networks. Foundation models in CV and NLP have shown powerful cross-domain capabilities that are also significant in graph domains. However, existing graph learning approaches struggle with cross-domain tasks. Inspired by successes in CV and NLP, cross-domain graph learning has once again become a focal point of attention to realizing true graph foundation models. In this survey, we present a comprehensive review and analysis of existing works on cross-domain graph learning. Concretely, we first propose a new taxonomy, categorizing existing approaches based on the learned cross-domain information: structure, feature, and structure-feature mixture. Next, we systematically survey representative methods in these categories. Finally, we discuss the remaining limitations of existing studies and highlight promising avenues for future research. Relevant papers are summarized and will be consistently updated at: https://github.com/cshhzhao/Awesome-Cross-Domain-Graph-Learning.
UniGAD: Unifying Multi-level Graph Anomaly Detection
Nov 10, 2024



Graph Anomaly Detection (GAD) aims to identify uncommon, deviated, or suspicious objects within graph-structured data. Existing methods generally focus on a single graph object type (node, edge, graph, etc.) and often overlook the inherent connections among different object types of graph anomalies. For instance, a money laundering transaction might involve an abnormal account and the broader community it interacts with. To address this, we present UniGAD, the first unified framework for detecting anomalies at node, edge, and graph levels jointly. Specifically, we develop the Maximum Rayleigh Quotient Subgraph Sampler (MRQSampler) that unifies multi-level formats by transferring objects at each level into graph-level tasks on subgraphs. We theoretically prove that MRQSampler maximizes the accumulated spectral energy of subgraphs (i.e., the Rayleigh quotient) to preserve the most significant anomaly information. To further unify multi-level training, we introduce a novel GraphStitch Network to integrate information across different levels, adjust the amount of sharing required at each level, and harmonize conflicting training goals. Comprehensive experiments show that UniGAD outperforms both existing GAD methods specialized for a single task and graph prompt-based approaches for multiple tasks, while also providing robust zero-shot task transferability. All codes can be found at https://github.com/lllyyq1121/UniGAD.
ProG: A Graph Prompt Learning Benchmark
Jun 08, 2024

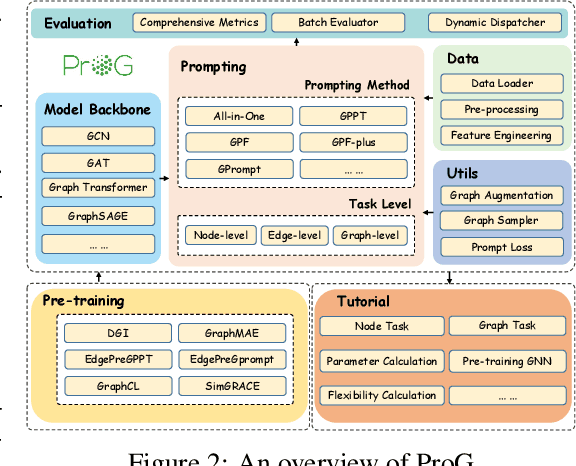

Artificial general intelligence on graphs has shown significant advancements across various applications, yet the traditional 'Pre-train & Fine-tune' paradigm faces inefficiencies and negative transfer issues, particularly in complex and few-shot settings. Graph prompt learning emerges as a promising alternative, leveraging lightweight prompts to manipulate data and fill the task gap by reformulating downstream tasks to the pretext. However, several critical challenges still remain: how to unify diverse graph prompt models, how to evaluate the quality of graph prompts, and to improve their usability for practical comparisons and selection. In response to these challenges, we introduce the first comprehensive benchmark for graph prompt learning. Our benchmark integrates SIX pre-training methods and FIVE state-of-the-art graph prompt techniques, evaluated across FIFTEEN diverse datasets to assess performance, flexibility, and efficiency. We also present 'ProG', an easy-to-use open-source library that streamlines the execution of various graph prompt models, facilitating objective evaluations. Additionally, we propose a unified framework that categorizes existing graph prompt methods into two main approaches: prompts as graphs and prompts as tokens. This framework enhances the applicability and comparison of graph prompt techniques. The code is available at: https://github.com/sheldonresearch/ProG.
Weakly Supervised Anomaly Detection via Knowledge-Data Alignment
Feb 06, 2024Anomaly detection (AD) plays a pivotal role in numerous web-based applications, including malware detection, anti-money laundering, device failure detection, and network fault analysis. Most methods, which rely on unsupervised learning, are hard to reach satisfactory detection accuracy due to the lack of labels. Weakly Supervised Anomaly Detection (WSAD) has been introduced with a limited number of labeled anomaly samples to enhance model performance. Nevertheless, it is still challenging for models, trained on an inadequate amount of labeled data, to generalize to unseen anomalies. In this paper, we introduce a novel framework Knowledge-Data Alignment (KDAlign) to integrate rule knowledge, typically summarized by human experts, to supplement the limited labeled data. Specifically, we transpose these rules into the knowledge space and subsequently recast the incorporation of knowledge as the alignment of knowledge and data. To facilitate this alignment, we employ the Optimal Transport (OT) technique. We then incorporate the OT distance as an additional loss term to the original objective function of WSAD methodologies. Comprehensive experimental results on five real-world datasets demonstrate that our proposed KDAlign framework markedly surpasses its state-of-the-art counterparts, achieving superior performance across various anomaly types.