 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated essay scoring using efficient transformer-based language models
Paper and Code
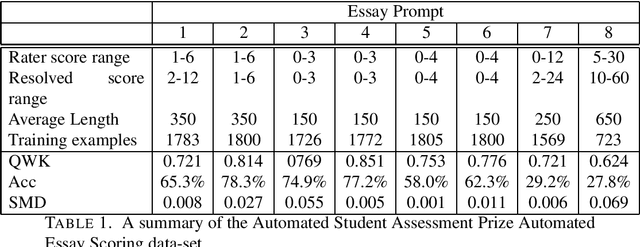
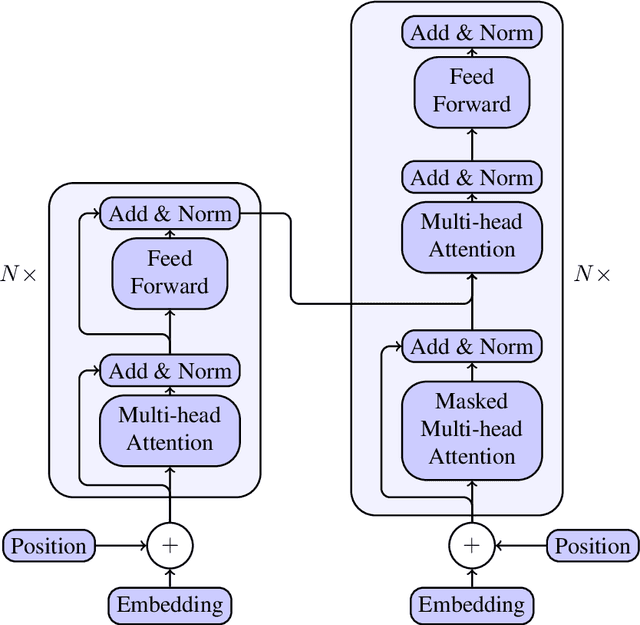
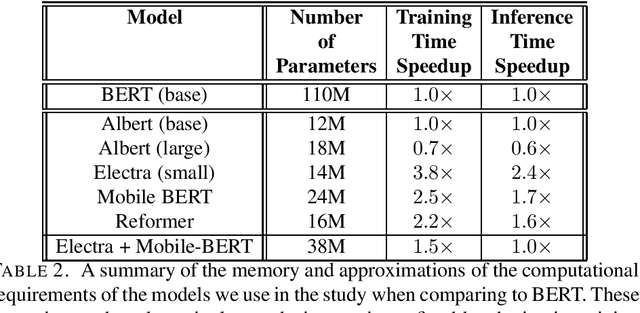
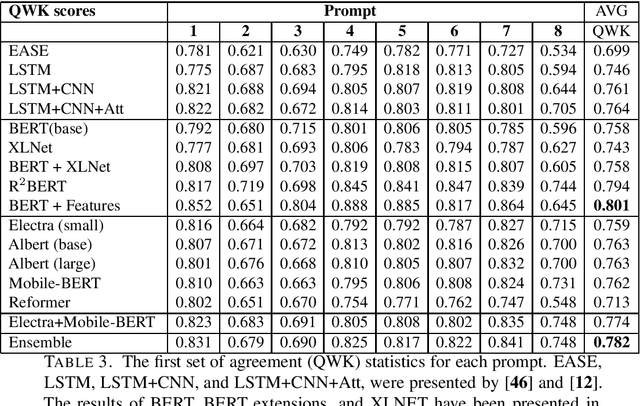
Automated Essay Scoring (AES) is a cross-disciplinary effort involving Education, Linguistics, and Natural Language Processing (NLP). The efficacy of an NLP model in AES tests it ability to evaluate long-term dependencies and extrapolate meaning even when text is poorly written. Large pretrained transformer-based language models have dominated the current state-of-the-art in many NLP tasks, however, the computational requirements of these models make them expensive to deploy in practice. The goal of this paper is to challenge the paradigm in NLP that bigger is better when it comes to AES. To do this, we evaluate the performance of several fine-tuned pretrained NLP models with a modest number of parameters on an AES dataset. By ensembling our models, we achieve excellent results with fewer parameters than most pretrained transformer-based models.