 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Item Characteristic Curves using Fine-Tuned Large Language Models
Jan 05, 2026Traditional methods for determining assessment item parameters, such as difficulty and discrimination, rely heavily on expensive field testing to collect student performance data for Item Response Theory (IRT) calibration. This study introduces a novel approach that implicitly models these psychometric properties by fine-tuning Large Language Models (LLMs) to simulate student responses across a spectrum of latent abilities. Leveraging the Qwen-3 dense model series and Low-Rank Adaptation (LoRA), we train models to generate responses to multiple choice questions conditioned on discrete ability descriptors. We reconstruct the probability of a correct response as a function of student ability, effectively generating synthetic Item Characteristic Curves (ICCs) to estimate IRT parameters. Evaluation on a dataset of Grade 6 English Language Arts (ELA) items and the BEA 2024 Shared Task dataset demonstrates that this method competes with or outperforms baseline approaches. This simulation-based technique seems particularly effective at modeling item discrimination.
Automated Essay Scoring Incorporating Annotations from Automated Feedback Systems
May 28, 2025This study illustrates how incorporating feedback-oriented annotations into the scoring pipeline can enhance the accuracy of automated essay scoring (AES). This approach is demonstrated with the Persuasive Essays for Rating, Selecting, and Understanding Argumentative and Discourse Elements (PERSUADE) corpus. We integrate two types of feedback-driven annotations: those that identify spelling and grammatical errors, and those that highlight argumentative components. To illustrate how this method could be applied in real-world scenarios, we employ two LLMs to generate annotations -- a generative language model used for spell-correction and an encoder-based token classifier trained to identify and mark argumentative elements. By incorporating annotations into the scoring process, we demonstrate improvements in performance using encoder-based large language models fine-tuned as classifiers.
Generative Language Models with Retrieval Augmented Generation for Automated Short Answer Scoring
Aug 07, 2024
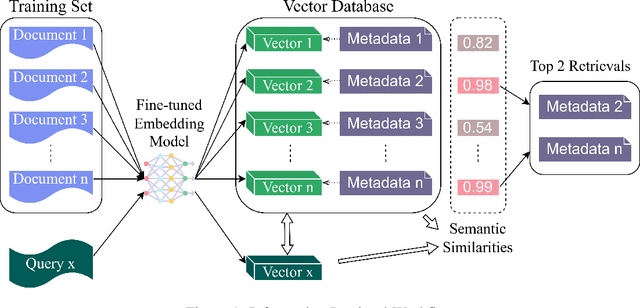
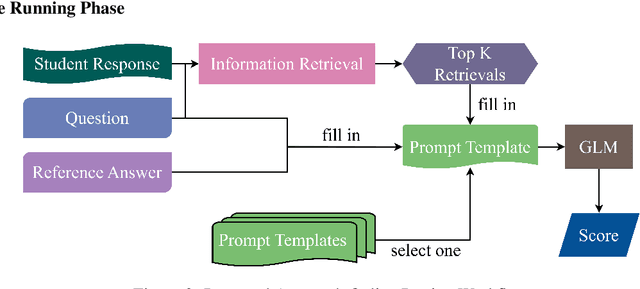
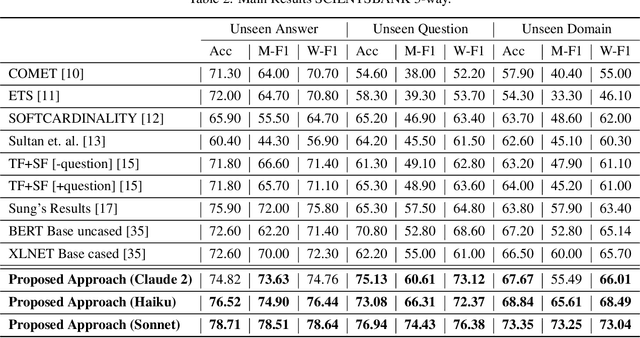
Automated Short Answer Scoring (ASAS) is a critical component in educational assessment. While traditional ASAS systems relied on rule-based algorithms or complex deep learning methods, recent advancements in Generative Language Models (GLMs) offer new opportunities for improvement. This study explores the application of GLMs to ASAS, leveraging their off-the-shelf capabilities and performance in various domains. We propose a novel pipeline that combines vector databases, transformer-based encoders, and GLMs to enhance short answer scoring accuracy. Our approach stores training responses in a vector database, retrieves semantically similar responses during inference, and employs a GLM to analyze these responses and determine appropriate scores. We further optimize the system through fine-tuned retrieval processes and prompt engineering. Evaluation on the SemEval 2013 dataset demonstrates a significant improvement on the SCIENTSBANK 3-way and 2-way tasks compared to existing methods, highlighting the potential of GLMs in advancing ASAS technology.
Argumentation Element Annotation Modeling using XLNet
Nov 10, 2023This study demonstrates the effectiveness of XLNet, a transformer-based language model, for annotating argumentative elements in persuasive essays. XLNet's architecture incorporates a recurrent mechanism that allows it to model long-term dependencies in lengthy texts. Fine-tuned XLNet models were applied to three datasets annotated with different schemes - a proprietary dataset using the Annotations for Revisions and Reflections on Writing (ARROW) scheme, the PERSUADE corpus, and the Argument Annotated Essays (AAE) dataset. The XLNet models achieved strong performance across all datasets, even surpassing human agreement levels in some cases. This shows XLNet capably handles diverse annotation schemes and lengthy essays. Comparisons between the model outputs on different datasets also revealed insights into the relationships between the annotation tags. Overall, XLNet's strong performance on modeling argumentative structures across diverse datasets highlights its suitability for providing automated feedback on essay organization.
Using language models in the implicit automated assessment of mathematical short answer items
Aug 21, 2023We propose a new way to assess certain short constructed responses to mathematics items. Our approach uses a pipeline that identifies the key values specified by the student in their response. This allows us to determine the correctness of the response, as well as identify any misconceptions. The information from the value identification pipeline can then be used to provide feedback to the teacher and student. The value identification pipeline consists of two fine-tuned language models. The first model determines if a value is implicit in the student response. The second model identifies where in the response the key value is specified. We consider both a generic model that can be used for any prompt and value, as well as models that are specific to each prompt and value. The value identification pipeline is a more accurate and informative way to assess short constructed responses than traditional rubric-based scoring. It can be used to provide more targeted feedback to students, which can help them improve their understanding of mathematics.
Short-answer scoring with ensembles of pretrained language models
Feb 23, 2022



We investigate the effectiveness of ensembles of pretrained transformer-based language models on short answer questions using the Kaggle Automated Short Answer Scoring dataset. We fine-tune a collection of popular small, base, and large pretrained transformer-based language models, and train one feature-base model on the dataset with the aim of testing ensembles of these models. We used an early stopping mechanism and hyperparameter optimization in training. We observe that generally that the larger models perform slightly better, however, they still fall short of state-of-the-art results one their own. Once we consider ensembles of models, there are ensembles of a number of large networks that do produce state-of-the-art results, however, these ensembles are too large to realistically be put in a production environment.
The effects of data size on Automated Essay Scoring engines
Aug 30, 2021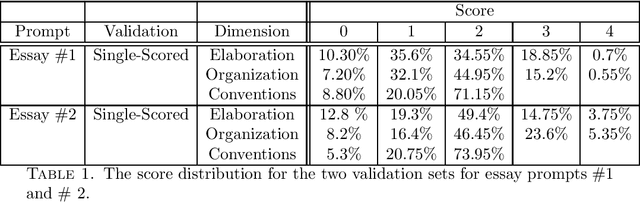
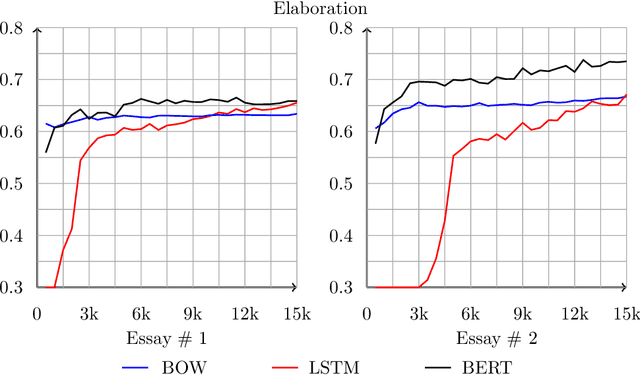
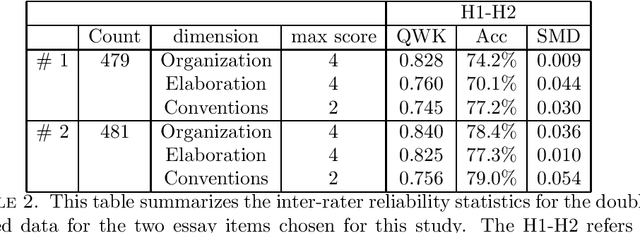
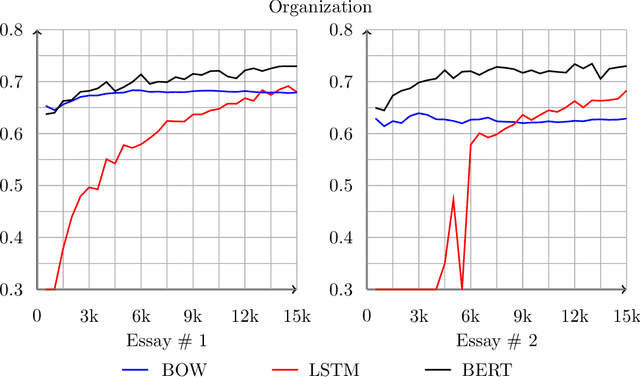
We study the effects of data size and quality on the performance on Automated Essay Scoring (AES) engines that are designed in accordance with three different paradigms; A frequency and hand-crafted feature-based model, a recurrent neural network model, and a pretrained transformer-based language model that is fine-tuned for classification. We expect that each type of model benefits from the size and the quality of the training data in very different ways. Standard practices for developing training data for AES engines were established with feature-based methods in mind, however, since neural networks are increasingly being considered in a production setting, this work seeks to inform us as to how to establish better training data for neural networks that will be used in production.