 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe effects of data size on Automated Essay Scoring engines
Aug 30, 2021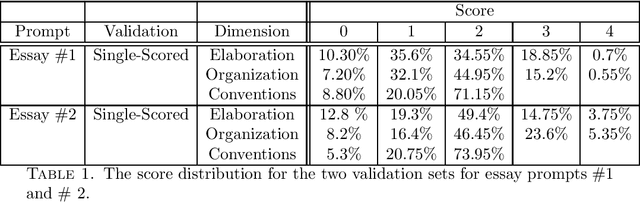
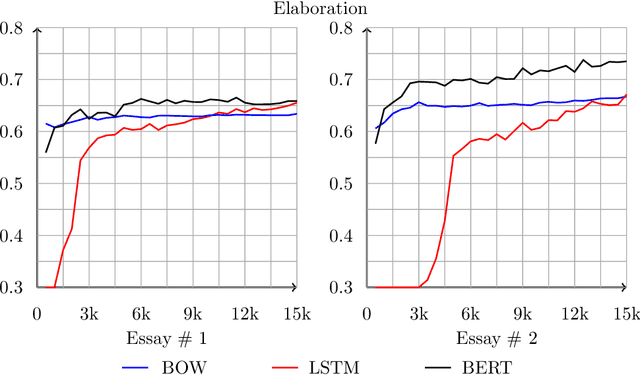
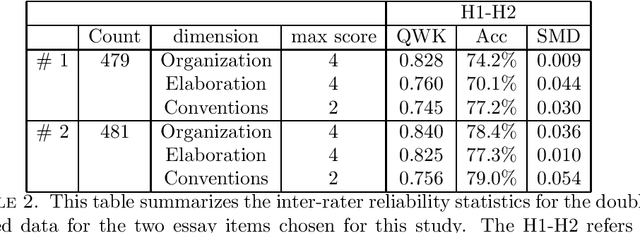
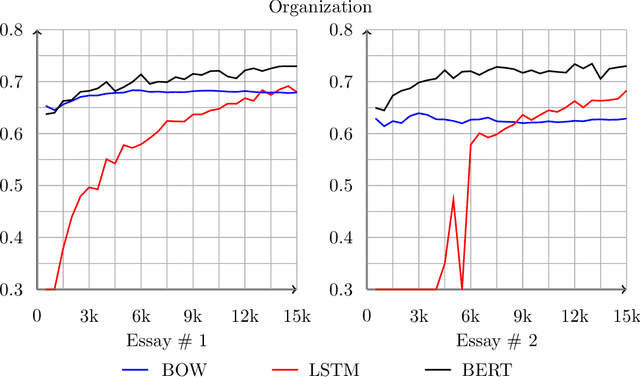
We study the effects of data size and quality on the performance on Automated Essay Scoring (AES) engines that are designed in accordance with three different paradigms; A frequency and hand-crafted feature-based model, a recurrent neural network model, and a pretrained transformer-based language model that is fine-tuned for classification. We expect that each type of model benefits from the size and the quality of the training data in very different ways. Standard practices for developing training data for AES engines were established with feature-based methods in mind, however, since neural networks are increasingly being considered in a production setting, this work seeks to inform us as to how to establish better training data for neural networks that will be used in production.