 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteligencia Artificial para la conservación y uso sostenible de la biodiversidad, una visión desde Colombia (Artificial Intelligence for conservation and sustainable use of biodiversity, a view from Colombia)
Mar 21, 2025



The rise of artificial intelligence (AI) and the aggravating biodiversity crisis have resulted in a research area where AI-based computational methods are being developed to act as allies in conservation, and the sustainable use and management of natural resources. While important general guidelines have been established globally regarding the opportunities and challenges that this interdisciplinary research offers, it is essential to generate local reflections from the specific contexts and realities of each region. Hence, this document aims to analyze the scope of this research area from a perspective focused on Colombia and the Neotropics. In this paper, we summarize the main experiences and debates that took place at the Humboldt Institute between 2023 and 2024 in Colombia. To illustrate the variety of promising opportunities, we present current uses such as automatic species identification from images and recordings, species modeling, and in silico bioprospecting, among others. From the experiences described above, we highlight limitations, challenges, and opportunities for in order to successfully implementate AI in conservation efforts and sustainable management of biological resources in the Neotropics. The result aims to be a guide for researchers, decision makers, and biodiversity managers, facilitating the understanding of how artificial intelligence can be effectively integrated into conservation and sustainable use strategies. Furthermore, it also seeks to open a space for dialogue on the development of policies that promote the responsible and ethical adoption of AI in local contexts, ensuring that its benefits are harnessed without compromising biodiversity or the cultural and ecosystemic values inherent in Colombia and the Neotropics.
Insect Identification in the Wild: The AMI Dataset
Jun 18, 2024
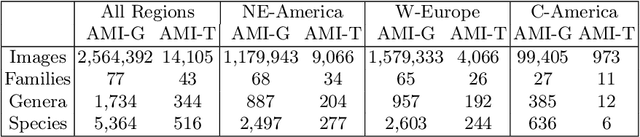


Insects represent half of all global biodiversity, yet many of the world's insects are disappearing, with severe implications for ecosystems and agriculture. Despite this crisis, data on insect diversity and abundance remain woefully inadequate, due to the scarcity of human experts and the lack of scalable tools for monitoring. Ecologists have started to adopt camera traps to record and study insects, and have proposed computer vision algorithms as an answer for scalable data processing. However, insect monitoring in the wild poses unique challenges that have not yet been addressed within computer vision, including the combination of long-tailed data, extremely similar classes, and significant distribution shifts. We provide the first large-scale machine learning benchmarks for fine-grained insect recognition, designed to match real-world tasks faced by ecologists. Our contributions include a curated dataset of images from citizen science platforms and museums, and an expert-annotated dataset drawn from automated camera traps across multiple continents, designed to test out-of-distribution generalization under field conditions. We train and evaluate a variety of baseline algorithms and introduce a combination of data augmentation techniques that enhance generalization across geographies and hardware setups. Code and datasets are made publicly available.
AnuraSet: A dataset for benchmarking Neotropical anuran calls identification in passive acoustic monitoring
Jul 11, 2023Global change is predicted to induce shifts in anuran acoustic behavior, which can be studied through passive acoustic monitoring (PAM). Understanding changes in calling behavior requires the identification of anuran species, which is challenging due to the particular characteristics of neotropical soundscapes. In this paper, we introduce a large-scale multi-species dataset of anuran amphibians calls recorded by PAM, that comprises 27 hours of expert annotations for 42 different species from two Brazilian biomes. We provide open access to the dataset, including the raw recordings, experimental setup code, and a benchmark with a baseline model of the fine-grained categorization problem. Additionally, we highlight the challenges of the dataset to encourage machine learning researchers to solve the problem of anuran call identification towards conservation policy. All our experiments and resources can be found on our GitHub repository https://github.com/soundclim/anuraset.