 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA machine learning pipeline for automated insect monitoring
Jun 18, 2024

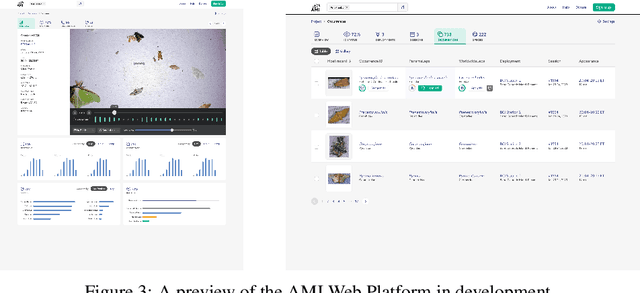

Climate change and other anthropogenic factors have led to a catastrophic decline in insects, endangering both biodiversity and the ecosystem services on which human society depends. Data on insect abundance, however, remains woefully inadequate. Camera traps, conventionally used for monitoring terrestrial vertebrates, are now being modified for insects, especially moths. We describe a complete, open-source machine learning-based software pipeline for automated monitoring of moths via camera traps, including object detection, moth/non-moth classification, fine-grained identification of moth species, and tracking individuals. We believe that our tools, which are already in use across three continents, represent the future of massively scalable data collection in entomology.
Insect Identification in the Wild: The AMI Dataset
Jun 18, 2024
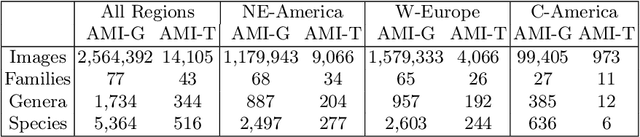


Insects represent half of all global biodiversity, yet many of the world's insects are disappearing, with severe implications for ecosystems and agriculture. Despite this crisis, data on insect diversity and abundance remain woefully inadequate, due to the scarcity of human experts and the lack of scalable tools for monitoring. Ecologists have started to adopt camera traps to record and study insects, and have proposed computer vision algorithms as an answer for scalable data processing. However, insect monitoring in the wild poses unique challenges that have not yet been addressed within computer vision, including the combination of long-tailed data, extremely similar classes, and significant distribution shifts. We provide the first large-scale machine learning benchmarks for fine-grained insect recognition, designed to match real-world tasks faced by ecologists. Our contributions include a curated dataset of images from citizen science platforms and museums, and an expert-annotated dataset drawn from automated camera traps across multiple continents, designed to test out-of-distribution generalization under field conditions. We train and evaluate a variety of baseline algorithms and introduce a combination of data augmentation techniques that enhance generalization across geographies and hardware setups. Code and datasets are made publicly available.
Bag of Tricks for Long-Tail Visual Recognition of Animal Species in Camera Trap Images
Jun 24, 2022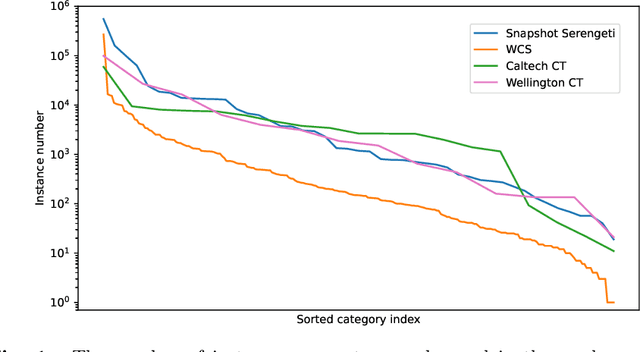
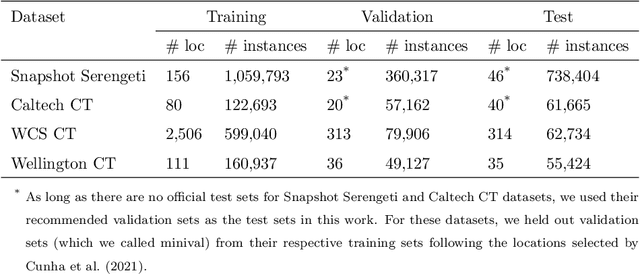


Camera traps are a strategy for monitoring wildlife that collects a large number of pictures. The number of images collected from each species usually follows a long-tail distribution, i.e., a few classes have a large number of instances while a lot of species have just a small percentage. Although in most cases these rare species are the classes of interest to ecologists, they are often neglected when using deep learning models because these models require a large number of images for the training. In this work, we systematically evaluate recently proposed techniques - namely, square-root re-sampling, class-balanced focal loss, and balanced group softmax - to address the long-tail visual recognition of animal species in camera trap images. To achieve a more general conclusion, we evaluated the selected methods on four families of computer vision models (ResNet, MobileNetV3, EfficientNetV2, and Swin Transformer) and four camera trap datasets with different characteristics. Initially, we prepared a robust baseline with the most recent training tricks and then we applied the methods for improving long-tail recognition. Our experiments show that the Swin transformer can reach high performance for rare classes without applying any additional method for handling imbalance, with an overall accuracy of 88.76% for WCS dataset and 94.97% for Snapshot Serengeti, considering a location-based train/test split. In general, the square-root sampling was the method that most improved the performance for minority classes by around 10%, but at the cost of reducing the majority classes accuracy at least 4%. These results motivated us to propose a simple and effective approach using an ensemble combining square-root sampling and the baseline. The proposed approach achieved the best trade-off between the performance of the tail class and the cost of the head classes' accuracy.
Filtering Empty Camera Trap Images in Embedded Systems
Apr 18, 2021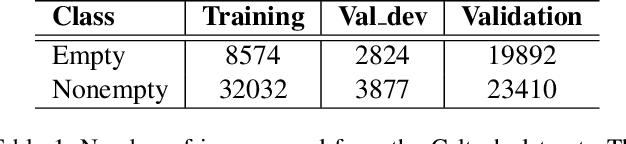
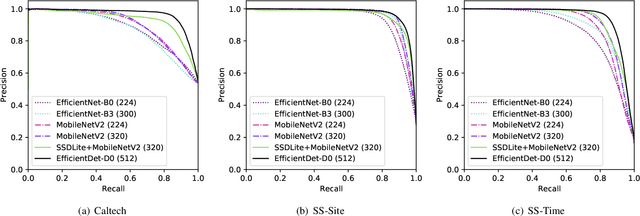


Monitoring wildlife through camera traps produces a massive amount of images, whose a significant portion does not contain animals, being later discarded. Embedding deep learning models to identify animals and filter these images directly in those devices brings advantages such as savings in the storage and transmission of data, usually resource-constrained in this type of equipment. In this work, we present a comparative study on animal recognition models to analyze the trade-off between precision and inference latency on edge devices. To accomplish this objective, we investigate classifiers and object detectors of various input resolutions and optimize them using quantization and reducing the number of model filters. The confidence threshold of each model was adjusted to obtain 96% recall for the nonempty class, since instances from the empty class are expected to be discarded. The experiments show that, when using the same set of images for training, detectors achieve superior performance, eliminating at least 10% more empty images than classifiers with comparable latencies. Considering the high cost of generating labels for the detection problem, when there is a massive number of images labeled for classification (about one million instances, ten times more than those available for detection), classifiers are able to reach results comparable to detectors but with half latency.