 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnakeVoxFormer: Transformer-based Single Image\\Voxel Reconstruction with Run Length Encoding
Paper and Code
Mar 28, 2023
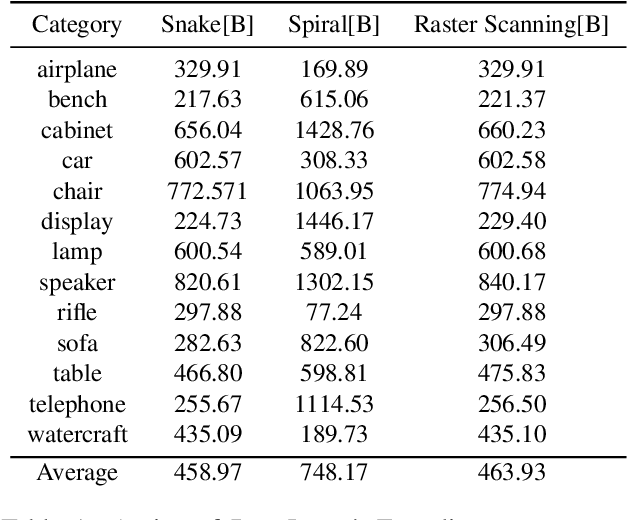

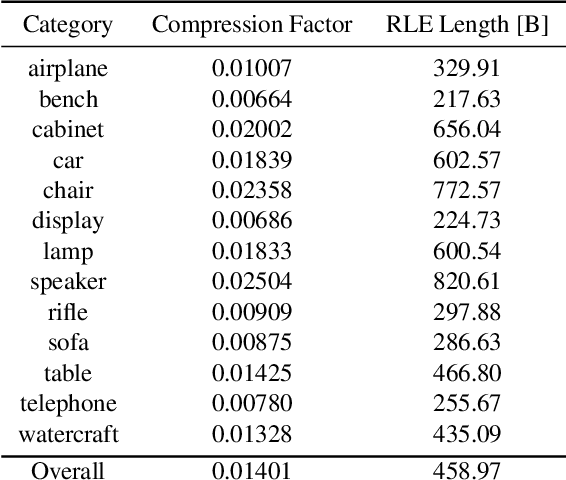
Deep learning-based 3D object reconstruction has achieved unprecedented results. Among those, the transformer deep neural model showed outstanding performance in many applications of computer vision. We introduce SnakeVoxFormer, a novel, 3D object reconstruction in voxel space from a single image using the transformer. The input to SnakeVoxFormer is a 2D image, and the result is a 3D voxel model. The key novelty of our approach is in using the run-length encoding that traverses (like a snake) the voxel space and encodes wide spatial differences into a 1D structure that is suitable for transformer encoding. We then use dictionary encoding to convert the discovered RLE blocks into tokens that are used for the transformer. The 1D representation is a lossless 3D shape data compression method that converts to 1D data that use only about 1% of the original data size. We show how different voxel traversing strategies affect the effect of encoding and reconstruction. We compare our method with the state-of-the-art for 3D voxel reconstruction from images and our method improves the state-of-the-art methods by at least 2.8% and up to 19.8%.