 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGB2Point: 3D Point Cloud Generation from Single RGB Images
Paper and Code
Jul 20, 2024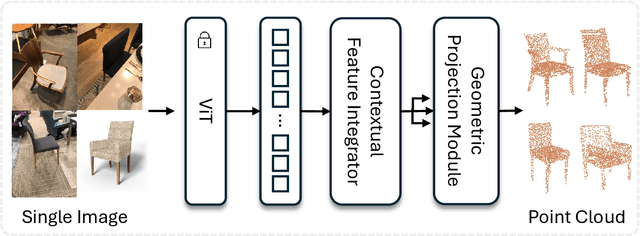
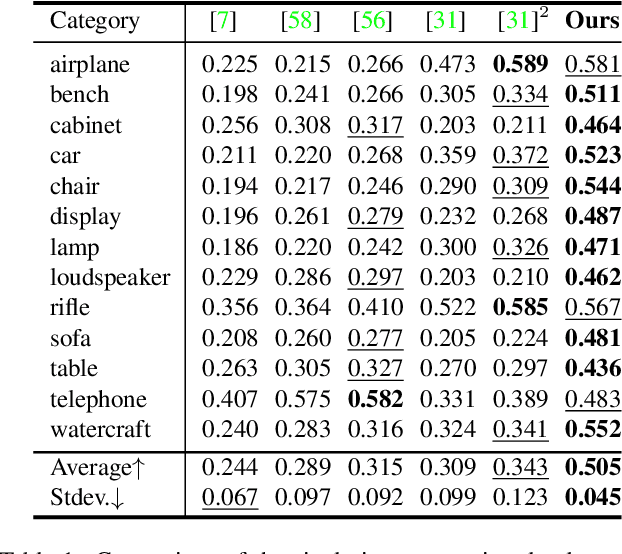

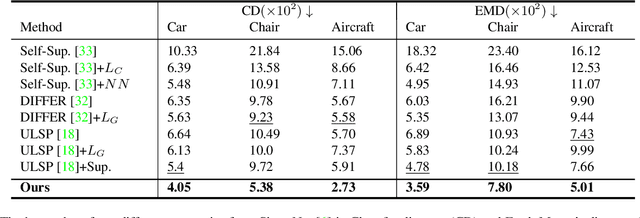
We introduce RGB2Point, an unposed single-view RGB image to a 3D point cloud generation based on Transformer. RGB2Point takes an input image of an object and generates a dense 3D point cloud. Contrary to prior works based on CNN layers and diffusion denoising approaches, we use pre-trained Transformer layers that are fast and generate high-quality point clouds with consistent quality over available categories. Our generated point clouds demonstrate high quality on a real-world dataset, as evidenced by improved Chamfer distance (51.15%) and Earth Mover's distance (45.96%) metrics compared to the current state-of-the-art. Additionally, our approach shows a better quality on a synthetic dataset, achieving better Chamfer distance (39.26%), Earth Mover's distance (26.95%), and F-score (47.16%). Moreover, our method produces 63.1% more consistent high-quality results across various object categories compared to prior works. Furthermore, RGB2Point is computationally efficient, requiring only 2.3GB of VRAM to reconstruct a 3D point cloud from a single RGB image, and our implementation generates the results 15,133x faster than a SOTA diffusion-based model.