 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Formation and Alignment in Language Models: Bridging Statistical Patterns in Latent Space to Concept Taxonomy
Paper and Code
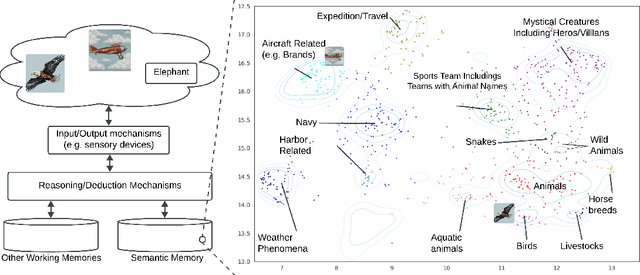

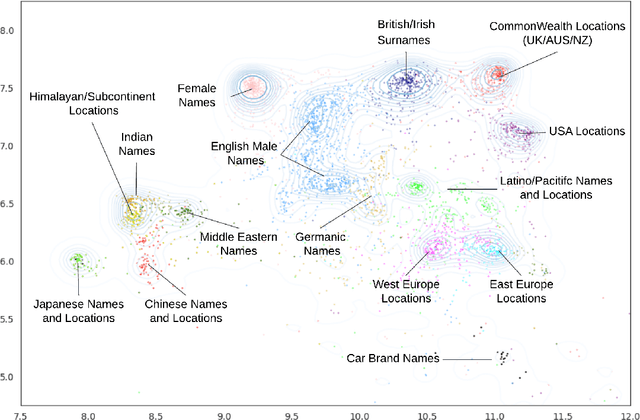
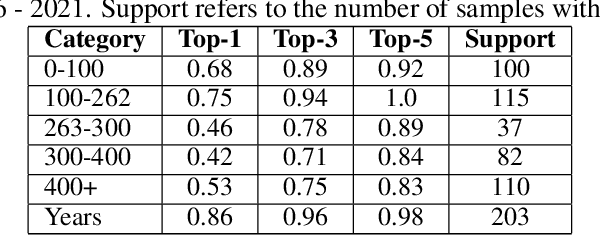
This paper explores the concept formation and alignment within the realm of language models (LMs). We propose a mechanism for identifying concepts and their hierarchical organization within the semantic representations learned by various LMs, encompassing a spectrum from early models like Glove to the transformer-based language models like ALBERT and T5. Our approach leverages the inherent structure present in the semantic embeddings generated by these models to extract a taxonomy of concepts and their hierarchical relationships. This investigation sheds light on how LMs develop conceptual understanding and opens doors to further research to improve their ability to reason and leverage real-world knowledge. We further conducted experiments and observed the possibility of isolating these extracted conceptual representations from the reasoning modules of the transformer-based LMs. The observed concept formation along with the isolation of conceptual representations from the reasoning modules can enable targeted token engineering to open the door for potential applications in knowledge transfer, explainable AI, and the development of more modular and conceptually grounded language models.