 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Retrieval with Semantic Tree-Structured Item Identifiers via Contrastive Learning
Paper and Code
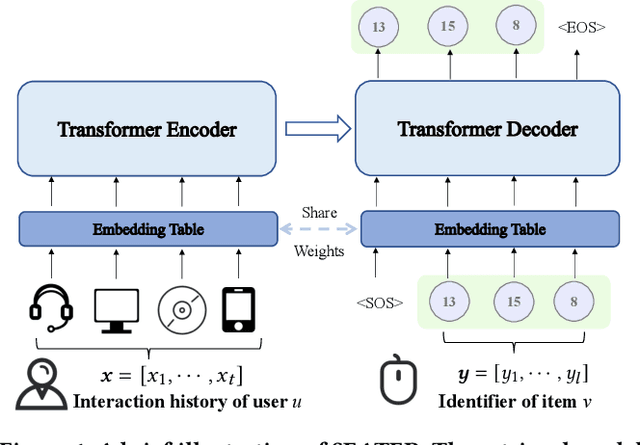
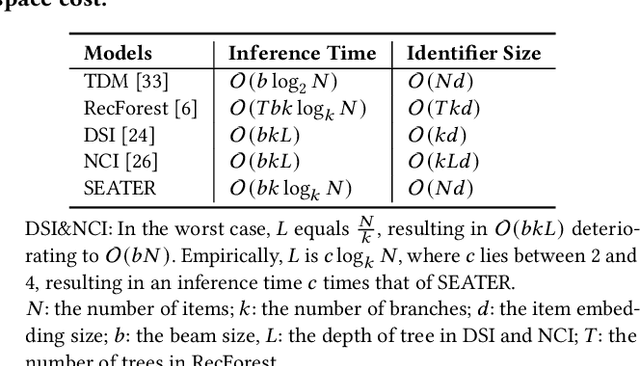
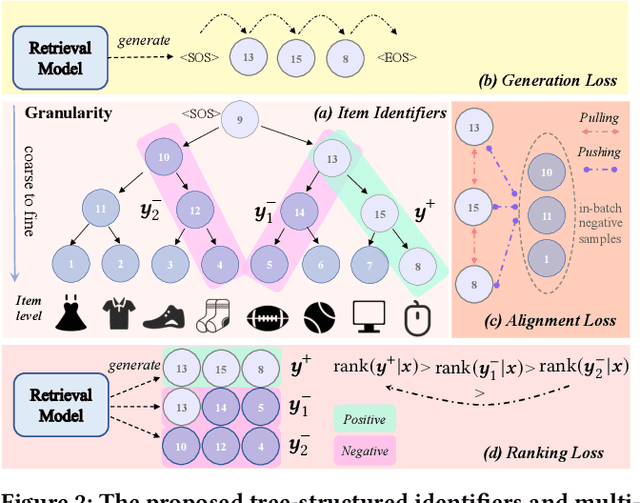
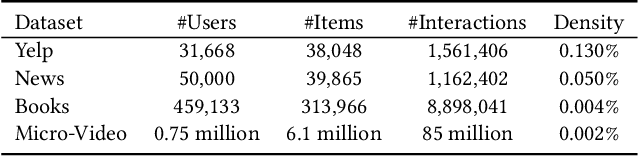
The retrieval phase is a vital component in recommendation systems, requiring the model to be effective and efficient. Recently, generative retrieval has become an emerging paradigm for document retrieval, showing notable performance. These methods enjoy merits like being end-to-end differentiable, suggesting their viability in recommendation. However, these methods fall short in efficiency and effectiveness for large-scale recommendations. To obtain efficiency and effectiveness, this paper introduces a generative retrieval framework, namely SEATER, which learns SEmAntic Tree-structured item identifiERs via contrastive learning. Specifically, we employ an encoder-decoder model to extract user interests from historical behaviors and retrieve candidates via tree-structured item identifiers. SEATER devises a balanced k-ary tree structure of item identifiers, allocating semantic space to each token individually. This strategy maintains semantic consistency within the same level, while distinct levels correlate to varying semantic granularities. This structure also maintains consistent and fast inference speed for all items. Considering the tree structure, SEATER learns identifier tokens' semantics, hierarchical relationships, and inter-token dependencies. To achieve this, we incorporate two contrastive learning tasks with the generation task to optimize both the model and identifiers. The infoNCE loss aligns the token embeddings based on their hierarchical positions. The triplet loss ranks similar identifiers in desired orders. In this way, SEATER achieves both efficiency and effectiveness. Extensive experiments on three public datasets and an industrial dataset have demonstrated that SEATER outperforms state-of-the-art models significantly.