 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFractional neural attention for efficient multiscale sequence processing
Nov 13, 2025Attention mechanisms underpin the computational power of Transformer models, which have achieved remarkable success across diverse domains. Yet understanding and extending the principles underlying self-attention remains a key challenge for advancing artificial intelligence. Drawing inspiration from the multiscale dynamics of biological attention and from dynamical systems theory, we introduce Fractional Neural Attention (FNA), a principled, neuroscience-inspired framework for multiscale information processing. FNA models token interactions through Lévy diffusion governed by the fractional Laplacian, intrinsically realizing simultaneous short- and long-range dependencies across multiple scales. This mechanism yields greater expressivity and faster information mixing, advancing the foundational capacity of Transformers. Theoretically, we show that FNA's dynamics are governed by the fractional diffusion equation, and that the resulting attention networks exhibit larger spectral gaps and shorter path lengths -- mechanistic signatures of enhanced computational efficiency. Empirically, FNA achieves competitive text-classification performance even with a single layer and a single head; it also improves performance in image processing and neural machine translation. Finally, the diffusion map algorithm from geometric harmonics enables dimensionality reduction of FNA weights while preserving the intrinsic structure of embeddings and hidden states. Together, these results establish FNA as a principled mechanism connecting self-attention, stochastic dynamics, and geometry, providing an interpretable, biologically grounded foundation for powerful, neuroscience-inspired AI.
Extended critical regimes of deep neural networks
Mar 24, 2022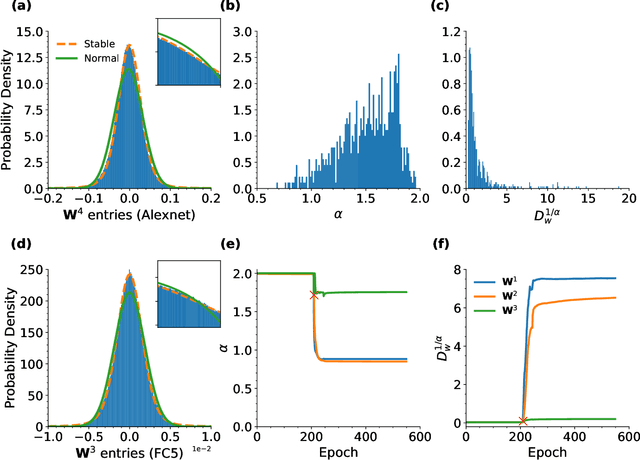

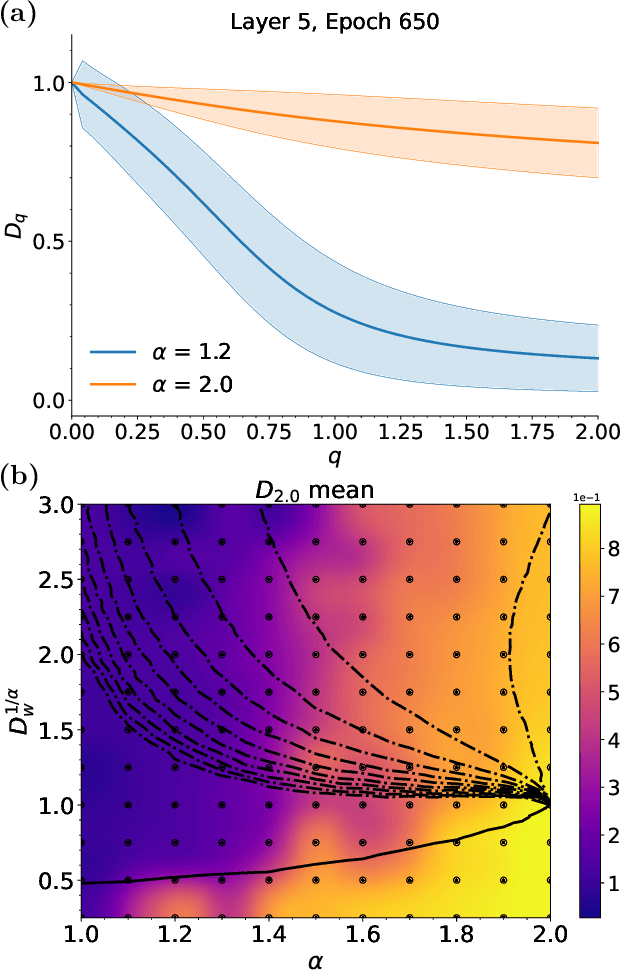
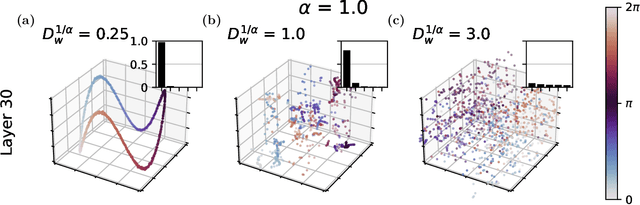
Deep neural networks (DNNs) have been successfully applied to many real-world problems, but a complete understanding of their dynamical and computational principles is still lacking. Conventional theoretical frameworks for analysing DNNs often assume random networks with coupling weights obeying Gaussian statistics. However, non-Gaussian, heavy-tailed coupling is a ubiquitous phenomenon in DNNs. Here, by weaving together theories of heavy-tailed random matrices and non-equilibrium statistical physics, we develop a new type of mean field theory for DNNs which predicts that heavy-tailed weights enable the emergence of an extended critical regime without fine-tuning parameters. In this extended critical regime, DNNs exhibit rich and complex propagation dynamics across layers. We further elucidate that the extended criticality endows DNNs with profound computational advantages: balancing the contraction as well as expansion of internal neural representations and speeding up training processes, hence providing a theoretical guide for the design of efficient neural architectures.
Anomalous diffusion dynamics of learning in deep neural networks
Sep 22, 2020



Learning in deep neural networks (DNNs) is implemented through minimizing a highly non-convex loss function, typically by a stochastic gradient descent (SGD) method. This learning process can effectively find good wide minima without being trapped in poor local ones. We present a novel account of how such effective deep learning emerges through the interactions of the SGD and the geometrical structure of the loss landscape. Rather than being a normal diffusion process (i.e. Brownian motion) as often assumed, we find that the SGD exhibits rich, complex dynamics when navigating through the loss landscape; initially, the SGD exhibits anomalous superdiffusion, which attenuates gradually and changes to subdiffusion at long times when the solution is reached. Such learning dynamics happen ubiquitously in different DNNs such as ResNet and VGG-like networks and are insensitive to batch size and learning rate. The anomalous superdiffusion process during the initial learning phase indicates that the motion of SGD along the loss landscape possesses intermittent, big jumps; this non-equilibrium property enables the SGD to escape from sharp local minima. By adapting the methods developed for studying energy landscapes in complex physical systems, we find that such superdiffusive learning dynamics are due to the interactions of the SGD and the fractal-like structure of the loss landscape. We further develop a simple model to demonstrate the mechanistic role of the fractal loss landscape in enabling the SGD to effectively find global minima. Our results thus reveal the effectiveness of deep learning from a novel perspective and have implications for designing efficient deep neural networks.