 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Deep-Learning NLP for Automating the Extraction of Oncology Efficacy Endpoints from Scientific Literature
Nov 03, 2023



Benchmarking drug efficacy is a critical step in clinical trial design and planning. The challenge is that much of the data on efficacy endpoints is stored in scientific papers in free text form, so extraction of such data is currently a largely manual task. Our objective is to automate this task as much as possible. In this study we have developed and optimised a framework to extract efficacy endpoints from text in scientific papers, using a machine learning approach. Our machine learning model predicts 25 classes associated with efficacy endpoints and leads to high F1 scores (harmonic mean of precision and recall) of 96.4% on the test set, and 93.9% and 93.7% on two case studies. These methods were evaluated against - and showed strong agreement with - subject matter experts and show significant promise in the future of automating the extraction of clinical endpoints from free text. Clinical information extraction from text data is currently a laborious manual task which scales poorly and is prone to human error. Demonstrating the ability to extract efficacy endpoints automatically shows great promise for accelerating clinical trial design moving forwards.
CLEARS - An Education and Research Tool for Computational Semantics
Aug 13, 1996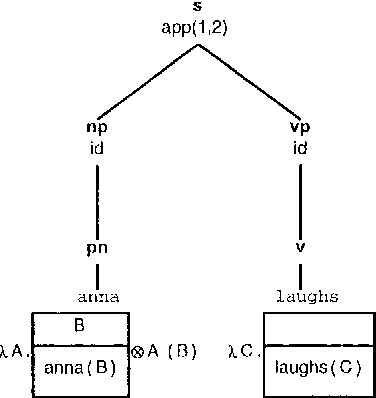
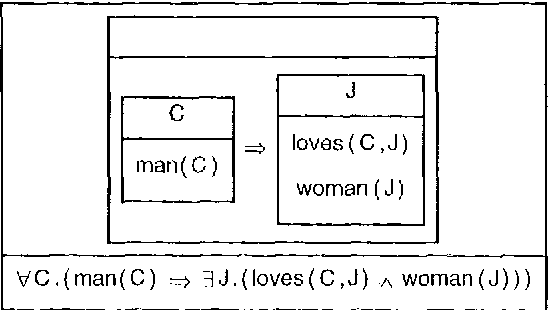
The CLEARS (Computational Linguistics Education and Research for Semantics) tool provides a graphical interface allowing interactive construction of semantic representations in a variety of different formalisms, and using several construction methods. CLEARS was developed as part of the FraCaS project which was designed to encourage convergence between different semantic formalisms, such as Montague-Grammar, DRT, and Situation Semantics. The CLEARS system is freely available on the WWW from http://coli.uni-sb.de/~clears/clears.html
Incremental Interpretation of Categorial Grammar
Mar 14, 1995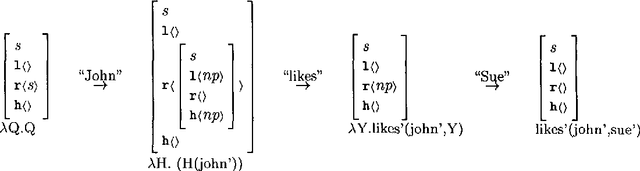
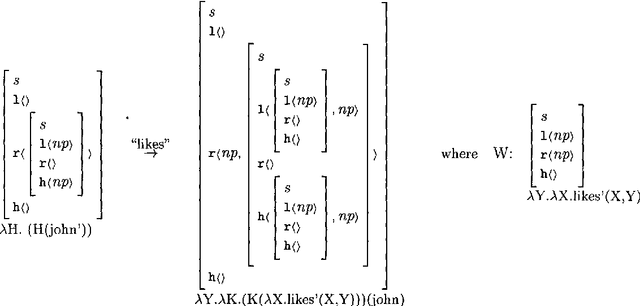
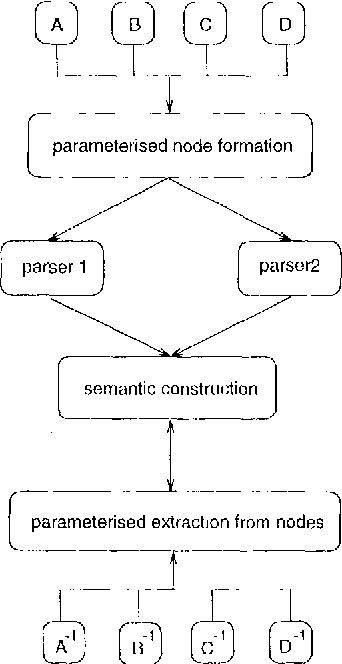
The paper describes a parser for Categorial Grammar which provides fully word by word incremental interpretation. The parser does not require fragments of sentences to form constituents, and thereby avoids problems of spurious ambiguity. The paper includes a brief discussion of the relationship between basic Categorial Grammar and other formalisms such as HPSG, Dependency Grammar and the Lambek Calculus. It also includes a discussion of some of the issues which arise when parsing lexicalised grammars, and the possibilities for using statistical techniques for tuning to particular languages.
Non-Constituent Coordination: Theory and Practice
Mar 14, 1995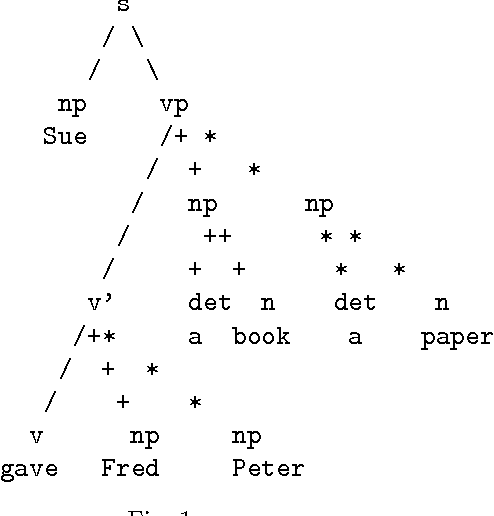
Despite the large amount of theoretical work done on non-constituent coordination during the last two decades, many computational systems still treat coordination using adapted parsing strategies, in a similar fashion to the SYSCONJ system developed for ATNs. This paper reviews the theoretical literature, and shows why many of the theoretical accounts actually have worse coverage than accounts based on processing. Finally, it shows how processing accounts can be described formally and declaratively in terms of Dynamic Grammars.
Incremental Interpretation: Applications, Theory, and Relationship to Dynamic Semantics
Mar 14, 1995Why should computers interpret language incrementally? In recent years psycholinguistic evidence for incremental interpretation has become more and more compelling, suggesting that humans perform semantic interpretation before constituent boundaries, possibly word by word. However, possible computational applications have received less attention. In this paper we consider various potential applications, in particular graphical interaction and dialogue. We then review the theoretical and computational tools available for mapping from fragments of sentences to fully scoped semantic representations. Finally, we tease apart the relationship between dynamic semantics and incremental interpretation.