 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyMatch -- Efficient Zero-Shot Entity Matching with a Small Language Model
Paper and Code

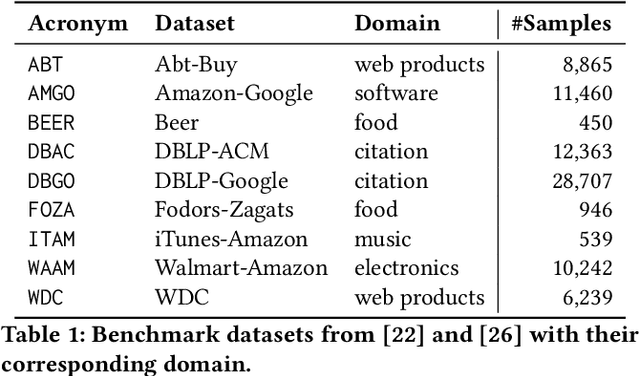
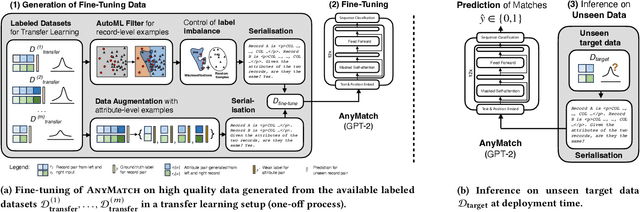
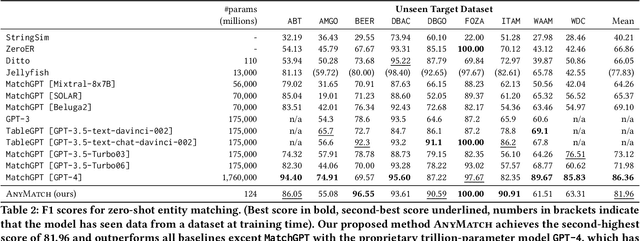
Entity matching (EM) is the problem of determining whether two records refer to same real-world entity, which is crucial in data integration, e.g., for product catalogs or address databases. A major drawback of many EM approaches is their dependence on labelled examples. We thus focus on the challenging setting of zero-shot entity matching where no labelled examples are available for an unseen target dataset. Recently, large language models (LLMs) have shown promising results for zero-shot EM, but their low throughput and high deployment cost limit their applicability and scalability. We revisit the zero-shot EM problem with AnyMatch, a small language model fine-tuned in a transfer learning setup. We propose several novel data selection techniques to generate fine-tuning data for our model, e.g., by selecting difficult pairs to match via an AutoML filter, by generating additional attribute-level examples, and by controlling label imbalance in the data. We conduct an extensive evaluation of the prediction quality and deployment cost of our model, in a comparison to thirteen baselines on nine benchmark datasets. We find that AnyMatch provides competitive prediction quality despite its small parameter size: it achieves the second-highest F1 score overall, and outperforms several other approaches that employ models with hundreds of billions of parameters. Furthermore, our approach exhibits major cost benefits: the average prediction quality of AnyMatch is within 4.4% of the state-of-the-art method MatchGPT with the proprietary trillion-parameter model GPT-4, yet AnyMatch requires four orders of magnitude less parameters and incurs a 3,899 times lower inference cost (in dollars per 1,000 tokens).