 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Automatic Speech Recognition Models with Disfluency Detection
Sep 17, 2024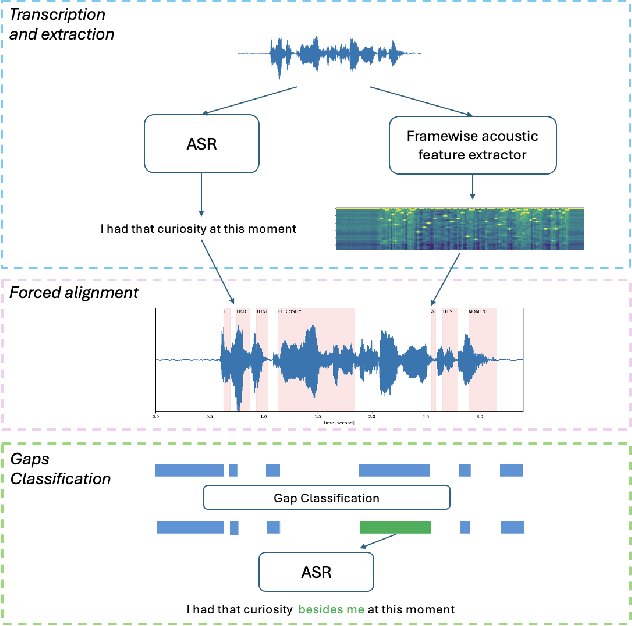

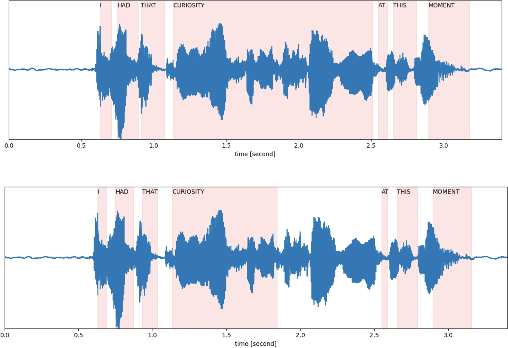

Speech disfluency commonly occurs in conversational and spontaneous speech. However, standard Automatic Speech Recognition (ASR) models struggle to accurately recognize these disfluencies because they are typically trained on fluent transcripts. Current research mainly focuses on detecting disfluencies within transcripts, overlooking their exact location and duration in the speech. Additionally, previous work often requires model fine-tuning and addresses limited types of disfluencies. In this work, we present an inference-only approach to augment any ASR model with the ability to detect open-set disfluencies. We first demonstrate that ASR models have difficulty transcribing speech disfluencies. Next, this work proposes a modified Connectionist Temporal Classification(CTC)-based forced alignment algorithm from \cite{kurzinger2020ctc} to predict word-level timestamps while effectively capturing disfluent speech. Additionally, we develop a model to classify alignment gaps between timestamps as either containing disfluent speech or silence. This model achieves an accuracy of 81.62% and an F1-score of 80.07%. We test the augmentation pipeline of alignment gap detection and classification on a disfluent dataset. Our results show that we captured 74.13% of the words that were initially missed by the transcription, demonstrating the potential of this pipeline for downstream tasks.