 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Jack of All Trades to Master of One: Specializing LLM-based Autoraters to a Test Set
Paper and Code
Nov 23, 2024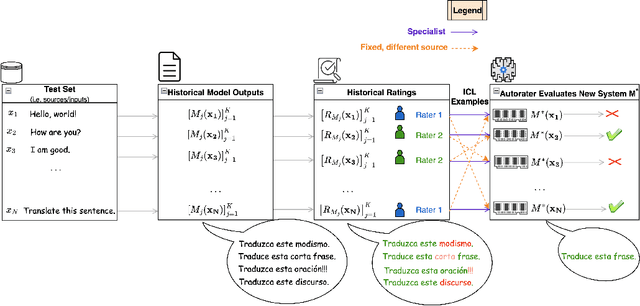

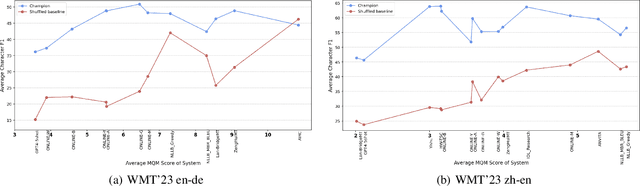

As LLMs continue to become more powerful and versatile, human evaluation has quickly become intractable at scale and reliance on automatic metrics has become the norm. Recently, it has been shown that LLMs are themselves state-of-the-art evaluators for many tasks. These Autoraters are typically designed so that they generalize to new systems and test sets. In practice, however, evaluation is performed on a small set of fixed, canonical test sets, which are carefully curated to measure certain capabilities of interest and are not changed frequently. In this work, we design a method which specializes a prompted Autorater to a given test set, by leveraging historical ratings on the test set to construct in-context learning (ICL) examples. We evaluate our Specialist method on the task of fine-grained machine translation evaluation, and show that it dramatically outperforms the state-of-the-art XCOMET metric by 54% and 119% on the WMT'23 and WMT'24 test sets, respectively. We perform extensive analyses to understand the representations learned by our Specialist metrics, and how variability in rater behavior affects their performance. We also verify the generalizability and robustness of our Specialist method for designing automatic metrics across different numbers of ICL examples, LLM backbones, systems to evaluate, and evaluation tasks.