 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconsidering the Past: Optimizing Hidden States in Language Models
Paper and Code



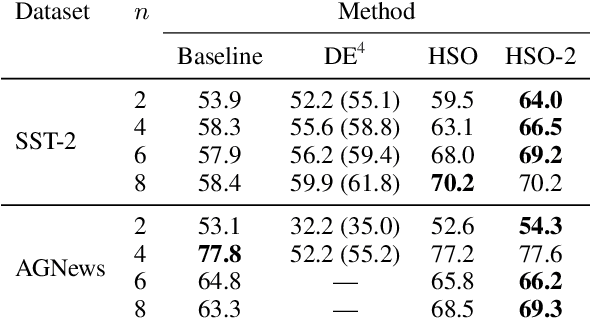
We present Hidden-State Optimization (HSO), a gradient-based method for improving the performance of transformer language models at inference time. Similar to dynamic evaluation (Krause et al., 2018), HSO computes the gradient of the log-probability the language model assigns to an evaluation text, but uses it to update the cached hidden states rather than the model parameters. We test HSO with pretrained Transformer-XL and GPT-2 language models, finding improvement on the WikiText103 and PG-19 datasets in terms of perplexity, especially when evaluating a model outside of its training distribution. We also demonstrate downstream applicability by showing gains in the recently developed prompt-based few-shot evaluation setting, again with no extra parameters or training data.