 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeqSAM: Autoregressive Multiple Hypothesis Prediction for Medical Image Segmentation using SAM
Mar 12, 2025
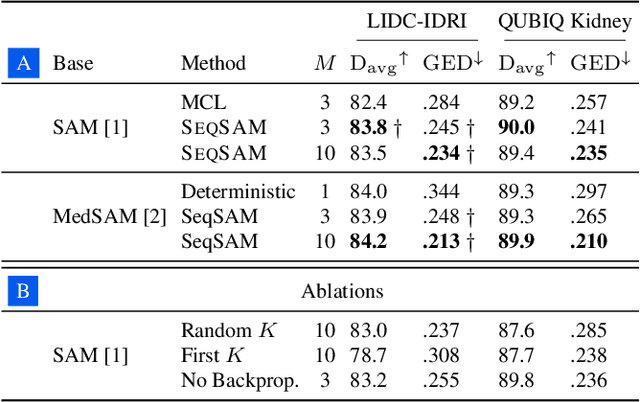
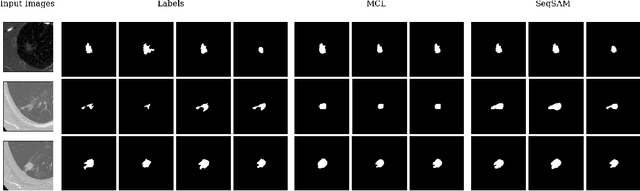
Pre-trained segmentation models are a powerful and flexible tool for segmenting images. Recently, this trend has extended to medical imaging. Yet, often these methods only produce a single prediction for a given image, neglecting inherent uncertainty in medical images, due to unclear object boundaries and errors caused by the annotation tool. Multiple Choice Learning is a technique for generating multiple masks, through multiple learned prediction heads. However, this cannot readily be extended to producing more outputs than its initial pre-training hyperparameters, as the sparse, winner-takes-all loss function makes it easy for one prediction head to become overly dominant, thus not guaranteeing the clinical relevancy of each mask produced. We introduce SeqSAM, a sequential, RNN-inspired approach to generating multiple masks, which uses a bipartite matching loss for ensuring the clinical relevancy of each mask, and can produce an arbitrary number of masks. We show notable improvements in quality of each mask produced across two publicly available datasets. Our code is available at https://github.com/BenjaminTowle/SeqSAM.
Enhancing AI Assisted Writing with One-Shot Implicit Negative Feedback
Oct 14, 2024



AI-mediated communication enables users to communicate more quickly and efficiently. Various systems have been proposed such as smart reply and AI-assisted writing. Yet, the heterogeneity of the forms of inputs and architectures often renders it challenging to combine insights from user behaviour in one system to improve performance in another. In this work, we consider the case where the user does not select any of the suggested replies from a smart reply system, and how this can be used as one-shot implicit negative feedback to enhance the accuracy of an AI writing model. We introduce Nifty, an approach that uses classifier guidance to controllably integrate implicit user feedback into the text generation process. Empirically, we find up to 34% improvement in Rouge-L, 89% improvement in generating the correct intent, and an 86% win-rate according to human evaluators compared to a vanilla AI writing system on the MultiWOZ and Schema-Guided Dialog datasets.
SimSAM: Zero-shot Medical Image Segmentation via Simulated Interaction
Jun 02, 2024


The recently released Segment Anything Model (SAM) has shown powerful zero-shot segmentation capabilities through a semi-automatic annotation setup in which the user can provide a prompt in the form of clicks or bounding boxes. There is growing interest around applying this to medical imaging, where the cost of obtaining expert annotations is high, privacy restrictions may limit sharing of patient data, and model generalisation is often poor. However, there are large amounts of inherent uncertainty in medical images, due to unclear object boundaries, low-contrast media, and differences in expert labelling style. Currently, SAM is known to struggle in a zero-shot setting to adequately annotate the contours of the structure of interest in medical images, where the uncertainty is often greatest, thus requiring significant manual correction. To mitigate this, we introduce \textbf{Sim}ulated Interaction for \textbf{S}egment \textbf{A}nything \textbf{M}odel (\textsc{\textbf{SimSAM}}), an approach that leverages simulated user interaction to generate an arbitrary number of candidate masks, and uses a novel aggregation approach to output the most compatible mask. Crucially, our method can be used during inference directly on top of SAM, without any additional training requirement. Quantitatively, we evaluate our method across three publicly available medical imaging datasets, and find that our approach leads to up to a 15.5\% improvement in contour segmentation accuracy compared to zero-shot SAM. Our code is available at \url{https://github.com/BenjaminTowle/SimSAM}.
End-to-End Autoregressive Retrieval via Bootstrapping for Smart Reply Systems
Oct 29, 2023



Reply suggestion systems represent a staple component of many instant messaging and email systems. However, the requirement to produce sets of replies, rather than individual replies, makes the task poorly suited for out-of-the-box retrieval architectures, which only consider individual message-reply similarity. As a result, these system often rely on additional post-processing modules to diversify the outputs. However, these approaches are ultimately bottlenecked by the performance of the initial retriever, which in practice struggles to present a sufficiently diverse range of options to the downstream diversification module, leading to the suggestions being less relevant to the user. In this paper, we consider a novel approach that radically simplifies this pipeline through an autoregressive text-to-text retrieval model, that learns the smart reply task end-to-end from a dataset of (message, reply set) pairs obtained via bootstrapping. Empirical results show this method consistently outperforms a range of state-of-the-art baselines across three datasets, corresponding to a 5.1%-17.9% improvement in relevance, and a 0.5%-63.1% improvement in diversity compared to the best baseline approach. We make our code publicly available.
Model-Based Simulation for Optimising Smart Reply
May 26, 2023Smart Reply (SR) systems present a user with a set of replies, of which one can be selected in place of having to type out a response. To perform well at this task, a system should be able to effectively present the user with a diverse set of options, to maximise the chance that at least one of them conveys the user's desired response. This is a significant challenge, due to the lack of datasets containing sets of responses to learn from. Resultantly, previous work has focused largely on post-hoc diversification, rather than explicitly learning to predict sets of responses. Motivated by this problem, we present a novel method SimSR, that employs model-based simulation to discover high-value response sets, through simulating possible user responses with a learned world model. Unlike previous approaches, this allows our method to directly optimise the end-goal of SR--maximising the relevance of at least one of the predicted replies. Empirically on two public datasets, when compared to SoTA baselines, our method achieves up to 21% and 18% improvement in ROUGE score and Self-ROUGE score respectively.
Learn What Is Possible, Then Choose What Is Best: Disentangling One-To-Many Relations in Language Through Text-based Games
Apr 26, 2023Language models pre-trained on large self-supervised corpora, followed by task-specific fine-tuning has become the dominant paradigm in NLP. These pre-training datasets often have a one-to-many structure--e.g. in dialogue there are many valid responses for a given context. However, only some of these responses will be desirable in our downstream task. This raises the question of how we should train the model such that it can emulate the desirable behaviours, but not the undesirable ones. Current approaches train in a one-to-one setup--only a single target response is given for a single dialogue context--leading to models only learning to predict the average response, while ignoring the full range of possible responses. Using text-based games as a testbed, our approach, PASA, uses discrete latent variables to capture the range of different behaviours represented in our larger pre-training dataset. We then use knowledge distillation to distil the posterior probability distribution into a student model. This probability distribution is far richer than learning from only the hard targets of the dataset, and thus allows the student model to benefit from the richer range of actions the teacher model has learned. Results show up to 49% empirical improvement over the previous state-of-the-art model on the Jericho Walkthroughs dataset.