 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-device Collaborative Computing for Multi-view Classification
Paper and Code
Sep 24, 2024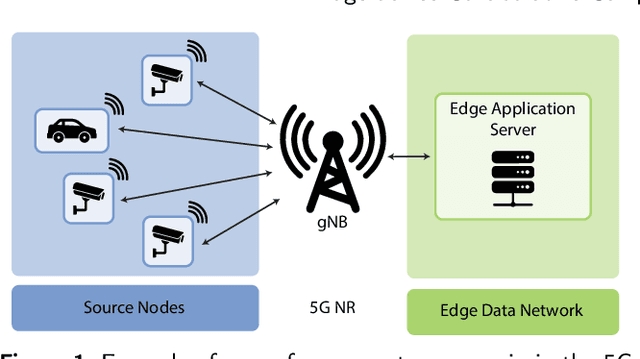

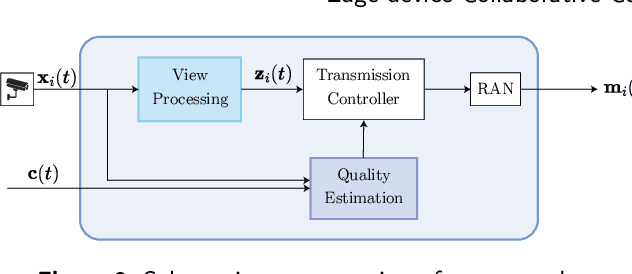

Motivated by the proliferation of Internet-of-Thing (IoT) devices and the rapid advances in the field of deep learning, there is a growing interest in pushing deep learning computations, conventionally handled by the cloud, to the edge of the network to deliver faster responses to end users, reduce bandwidth consumption to the cloud, and address privacy concerns. However, to fully realize deep learning at the edge, two main challenges still need to be addressed: (i) how to meet the high resource requirements of deep learning on resource-constrained devices, and (ii) how to leverage the availability of multiple streams of spatially correlated data, to increase the effectiveness of deep learning and improve application-level performance. To address the above challenges, we explore collaborative inference at the edge, in which edge nodes and end devices share correlated data and the inference computational burden by leveraging different ways to split computation and fuse data. Besides traditional centralized and distributed schemes for edge-end device collaborative inference, we introduce selective schemes that decrease bandwidth resource consumption by effectively reducing data redundancy. As a reference scenario, we focus on multi-view classification in a networked system in which sensing nodes can capture overlapping fields of view. The proposed schemes are compared in terms of accuracy, computational expenditure at the nodes, communication overhead, inference latency, robustness, and noise sensitivity. Experimental results highlight that selective collaborative schemes can achieve different trade-offs between the above performance metrics, with some of them bringing substantial communication savings (from 18% to 74% of the transmitted data with respect to centralized inference) while still keeping the inference accuracy well above 90%.