 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilingual Dual-Head Deep Model for Parkinson's Disease Detection from Speech
Mar 13, 2025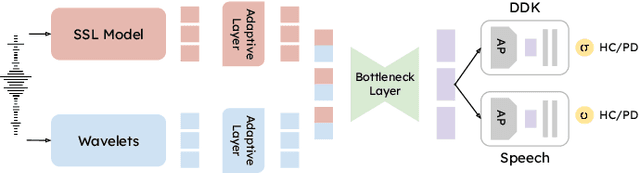
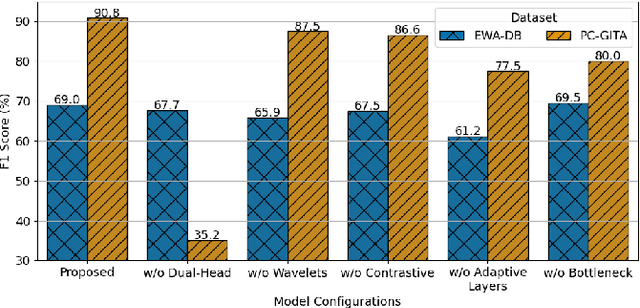
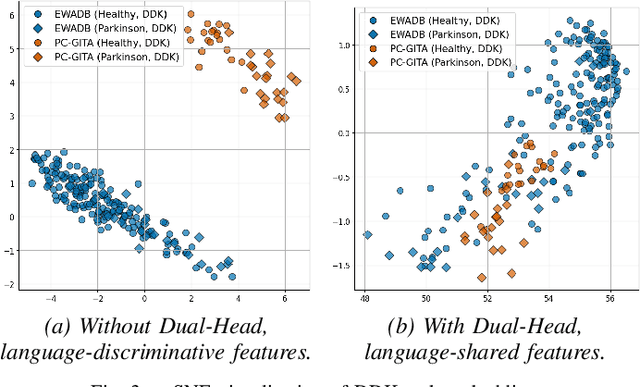
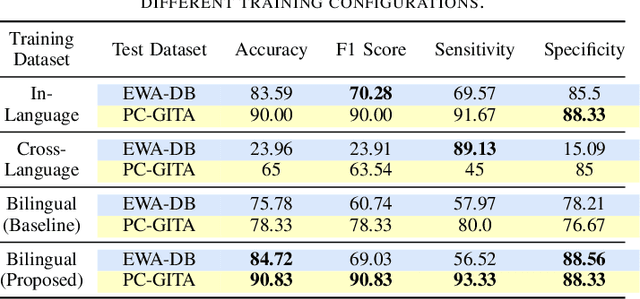
This work aims to tackle the Parkinson's disease (PD) detection problem from the speech signal in a bilingual setting by proposing an ad-hoc dual-head deep neural architecture for type-based binary classification. One head is specialized for diadochokinetic patterns. The other head looks for natural speech patterns present in continuous spoken utterances. Only one of the two heads is operative accordingly to the nature of the input. Speech representations are extracted from self-supervised learning (SSL) models and wavelet transforms. Adaptive layers, convolutional bottlenecks, and contrastive learning are exploited to reduce variations across languages. Our solution is assessed against two distinct datasets, EWA-DB, and PC-GITA, which cover Slovak and Spanish languages, respectively. Results indicate that conventional models trained on a single language dataset struggle with cross-linguistic generalization, and naive combinations of datasets are suboptimal. In contrast, our model improves generalization on both languages, simultaneously.
voc2vec: A Foundation Model for Non-Verbal Vocalization
Feb 22, 2025



Speech foundation models have demonstrated exceptional capabilities in speech-related tasks. Nevertheless, these models often struggle with non-verbal audio data, such as vocalizations, baby crying, etc., which are critical for various real-world applications. Audio foundation models well handle non-speech data but also fail to capture the nuanced features of non-verbal human sounds. In this work, we aim to overcome the above shortcoming and propose a novel foundation model, termed voc2vec, specifically designed for non-verbal human data leveraging exclusively open-source non-verbal audio datasets. We employ a collection of 10 datasets covering around 125 hours of non-verbal audio. Experimental results prove that voc2vec is effective in non-verbal vocalization classification, and it outperforms conventional speech and audio foundation models. Moreover, voc2vec consistently outperforms strong baselines, namely OpenSmile and emotion2vec, on six different benchmark datasets. To the best of the authors' knowledge, voc2vec is the first universal representation model for vocalization tasks.