 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Distributional Bias in Multi-Round LLM Generation via KL-Optimized Fine-Tuning
Apr 07, 2026While the real world is inherently stochastic, Large Language Models (LLMs) are predominantly evaluated on single-round inference against fixed ground truths. In this work, we shift the lens to distribution alignment: assessing whether LLMs, when prompted repeatedly, can generate outputs that adhere to a desired target distribution, e.g. reflecting real-world statistics or a uniform distribution. We formulate distribution alignment using the attributes of gender, race, and sentiment within occupational contexts. Our empirical analysis reveals that off-the-shelf LLMs and standard alignment techniques, including prompt engineering and Direct Preference Optimization, fail to reliably control output distributions. To bridge this gap, we propose a novel fine-tuning framework that couples Steering Token Calibration with Semantic Alignment. We introduce a hybrid objective function combining Kullback-Leibler divergence to anchor the probability mass of latent steering tokens and Kahneman-Tversky Optimization to bind these tokens to semantically consistent responses. Experiments across six diverse datasets demonstrate that our approach significantly outperforms baselines, achieving precise distributional control in attribute generation tasks.
Attention in Space: Functional Roles of VLM Heads for Spatial Reasoning
Mar 21, 2026Despite remarkable advances in large Vision-Language Models (VLMs), spatial reasoning remains a persistent challenge. In this work, we investigate how attention heads within VLMs contribute to spatial reasoning by analyzing their functional roles through a mechanistic interpretability lens. We introduce CogVSR, a dataset that decomposes complex spatial reasoning questions into step-by-step subquestions designed to simulate human-like reasoning via a chain-of-thought paradigm, with each subquestion linked to specific cognitive functions such as spatial perception or relational reasoning. Building on CogVSR, we develop a probing framework to identify and characterize attention heads specialized for these functions. Our analysis across diverse VLM families reveals that these functional heads are universally sparse, vary in number and distribution across functions. Notably, spatially specialized heads are fewer than those for other cognitive functions, highlighting their scarcity. We propose methods to activate latent spatial heads, improving spatial understanding. Intervention experiments further demonstrate their critical role in spatial reasoning: removing functional heads leads to performance degradation, while emphasizing them enhances accuracy. This study provides new interpretability driven insights into how VLMs attend to space and paves the way for enhancing complex spatial reasoning in multimodal models.
Investigating The Functional Roles of Attention Heads in Vision Language Models: Evidence for Reasoning Modules
Dec 11, 2025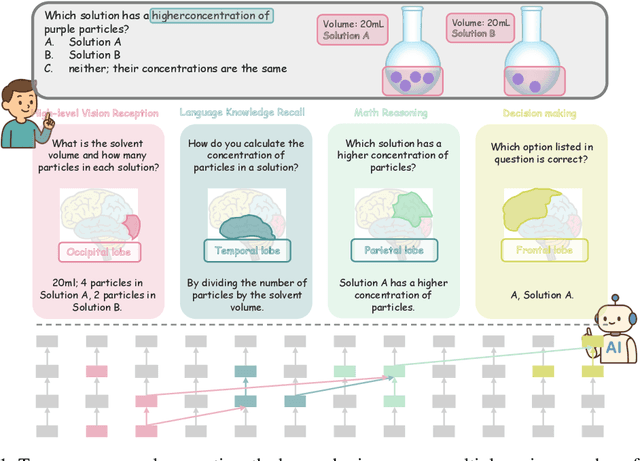
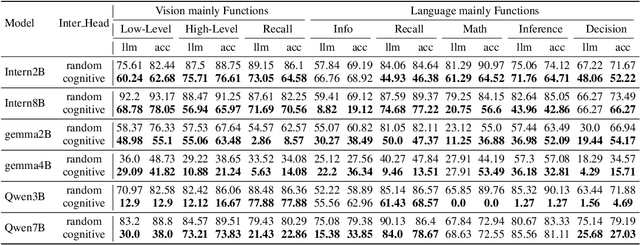
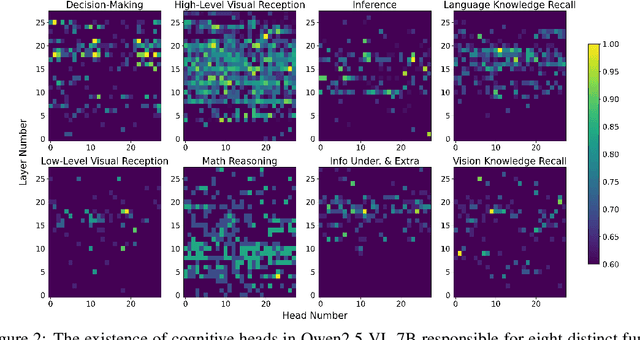

Despite excelling on multimodal benchmarks, vision-language models (VLMs) largely remain a black box. In this paper, we propose a novel interpretability framework to systematically analyze the internal mechanisms of VLMs, focusing on the functional roles of attention heads in multimodal reasoning. To this end, we introduce CogVision, a dataset that decomposes complex multimodal questions into step-by-step subquestions designed to simulate human reasoning through a chain-of-thought paradigm, with each subquestion associated with specific receptive or cognitive functions such as high-level visual reception and inference. Using a probing-based methodology, we identify attention heads that specialize in these functions and characterize them as functional heads. Our analysis across diverse VLM families reveals that these functional heads are universally sparse, vary in number and distribution across functions, and mediate interactions and hierarchical organization. Furthermore, intervention experiments demonstrate their critical role in multimodal reasoning: removing functional heads leads to performance degradation, while emphasizing them enhances accuracy. These findings provide new insights into the cognitive organization of VLMs and suggest promising directions for designing models with more human-aligned perceptual and reasoning abilities.
PROPA: Toward Process-level Optimization in Visual Reasoning via Reinforcement Learning
Nov 13, 2025Despite significant progress, Vision-Language Models (VLMs) still struggle with complex visual reasoning, where multi-step dependencies cause early errors to cascade through the reasoning chain. Existing post-training paradigms are limited: Supervised Fine-Tuning (SFT) relies on costly step-level annotations, while Reinforcement Learning with Verifiable Rewards (RLVR) methods like GRPO provide only sparse, outcome-level feedback, hindering stable optimization. We introduce PROPA (Process-level Reasoning Optimization with interleaved Policy Alignment), a novel framework that integrates Monte Carlo Tree Search (MCTS) with GRPO to generate dense, process-level rewards and optimize reasoning at each intermediate step without human annotations. To overcome the cold-start problem, PROPA interleaves GRPO updates with SFT, enabling the model to learn from both successful and failed reasoning trajectories. A Process Reward Model (PRM) is further trained to guide inference-time search, aligning the test-time search with the training signal. Across seven benchmarks and four VLM backbones, PROPA consistently outperforms both SFT- and RLVR-based baselines. It achieves up to 17.0% gains on in-domain tasks and 21.0% gains on out-of-domain tasks compared to existing state-of-the-art, establishing a strong reasoning and generalization capability for visual reasoning tasks. The code isavailable at: https://github.com/YanbeiJiang/PROPA.
Beyond Perception: Evaluating Abstract Visual Reasoning through Multi-Stage Task
May 28, 2025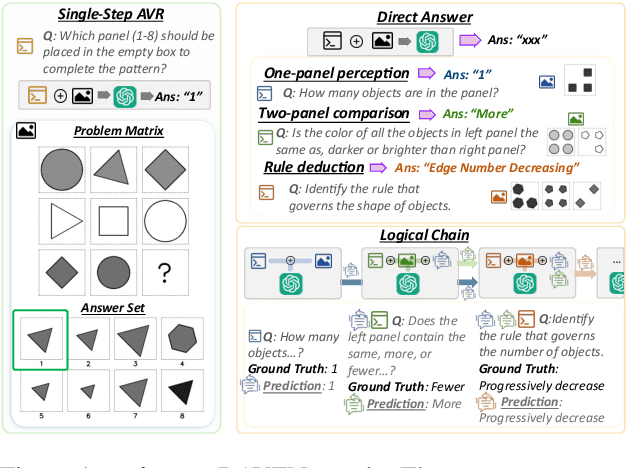
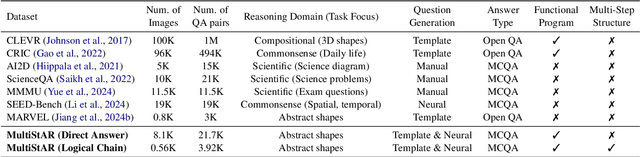
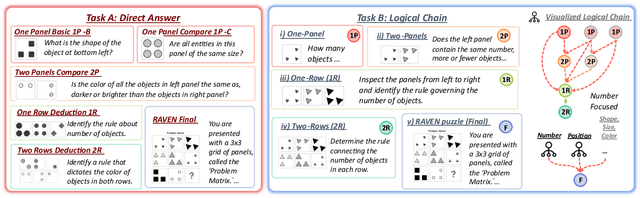
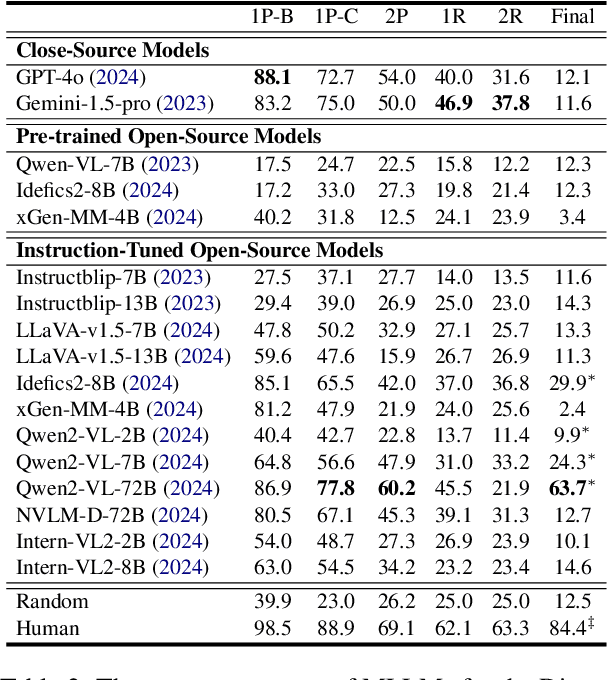
Current Multimodal Large Language Models (MLLMs) excel in general visual reasoning but remain underexplored in Abstract Visual Reasoning (AVR), which demands higher-order reasoning to identify abstract rules beyond simple perception. Existing AVR benchmarks focus on single-step reasoning, emphasizing the end result but neglecting the multi-stage nature of reasoning process. Past studies found MLLMs struggle with these benchmarks, but it doesn't explain how they fail. To address this gap, we introduce MultiStAR, a Multi-Stage AVR benchmark, based on RAVEN, designed to assess reasoning across varying levels of complexity. Additionally, existing metrics like accuracy only focus on the final outcomes while do not account for the correctness of intermediate steps. Therefore, we propose a novel metric, MSEval, which considers the correctness of intermediate steps in addition to the final outcomes. We conduct comprehensive experiments on MultiStAR using 17 representative close-source and open-source MLLMs. The results reveal that while existing MLLMs perform adequately on basic perception tasks, they continue to face challenges in more complex rule detection stages.
Open-World Amodal Appearance Completion
Nov 20, 2024Understanding and reconstructing occluded objects is a challenging problem, especially in open-world scenarios where categories and contexts are diverse and unpredictable. Traditional methods, however, are typically restricted to closed sets of object categories, limiting their use in complex, open-world scenes. We introduce Open-World Amodal Appearance Completion, a training-free framework that expands amodal completion capabilities by accepting flexible text queries as input. Our approach generalizes to arbitrary objects specified by both direct terms and abstract queries. We term this capability reasoning amodal completion, where the system reconstructs the full appearance of the queried object based on the provided image and language query. Our framework unifies segmentation, occlusion analysis, and inpainting to handle complex occlusions and generates completed objects as RGBA elements, enabling seamless integration into applications such as 3D reconstruction and image editing. Extensive evaluations demonstrate the effectiveness of our approach in generalizing to novel objects and occlusions, establishing a new benchmark for amodal completion in open-world settings. The code and datasets will be released after paper acceptance.
KALE: An Artwork Image Captioning System Augmented with Heterogeneous Graph
Sep 17, 2024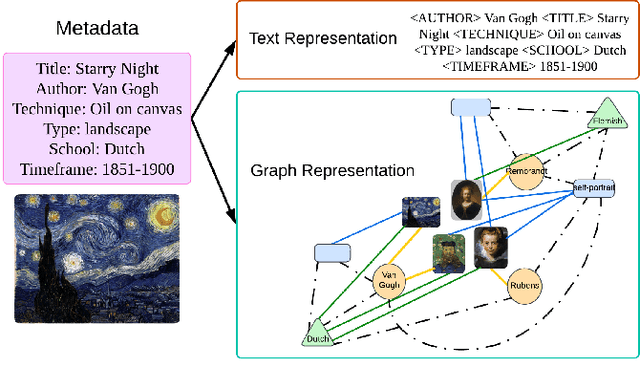
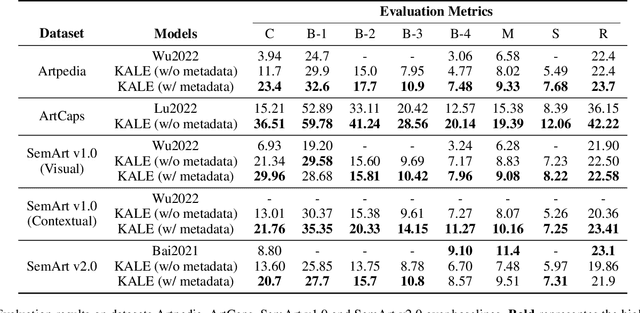
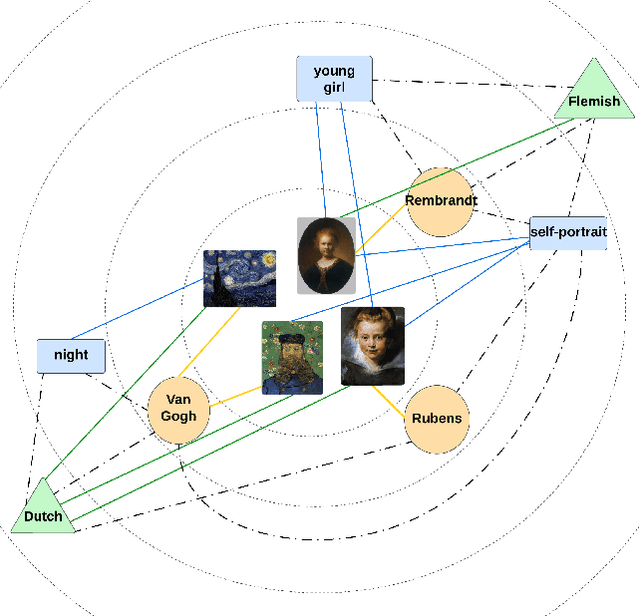
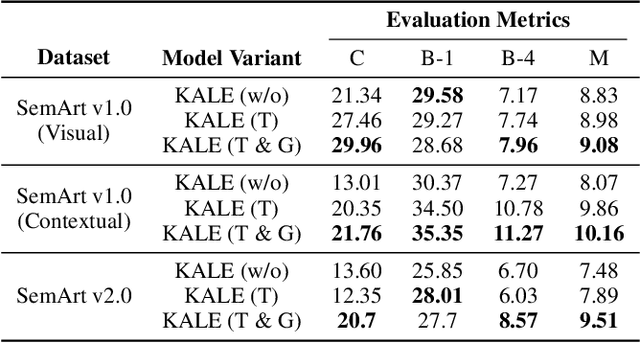
Exploring the narratives conveyed by fine-art paintings is a challenge in image captioning, where the goal is to generate descriptions that not only precisely represent the visual content but also offer a in-depth interpretation of the artwork's meaning. The task is particularly complex for artwork images due to their diverse interpretations and varied aesthetic principles across different artistic schools and styles. In response to this, we present KALE Knowledge-Augmented vision-Language model for artwork Elaborations), a novel approach that enhances existing vision-language models by integrating artwork metadata as additional knowledge. KALE incorporates the metadata in two ways: firstly as direct textual input, and secondly through a multimodal heterogeneous knowledge graph. To optimize the learning of graph representations, we introduce a new cross-modal alignment loss that maximizes the similarity between the image and its corresponding metadata. Experimental results demonstrate that KALE achieves strong performance (when evaluated with CIDEr, in particular) over existing state-of-the-art work across several artwork datasets. Source code of the project is available at https://github.com/Yanbei-Jiang/Artwork-Interpretation.