 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKALE: An Artwork Image Captioning System Augmented with Heterogeneous Graph
Paper and Code
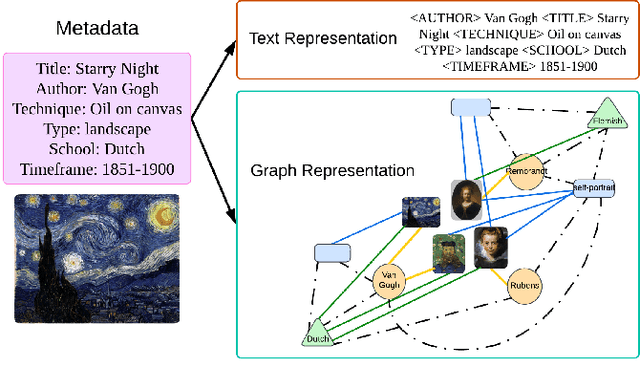
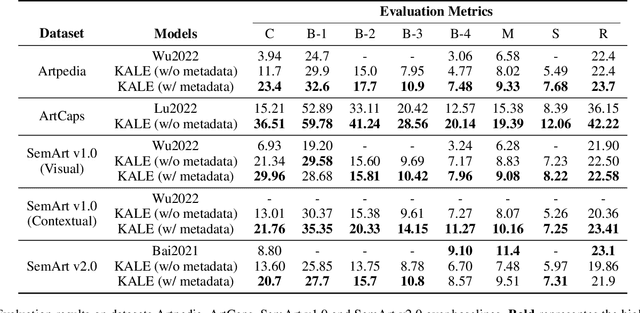
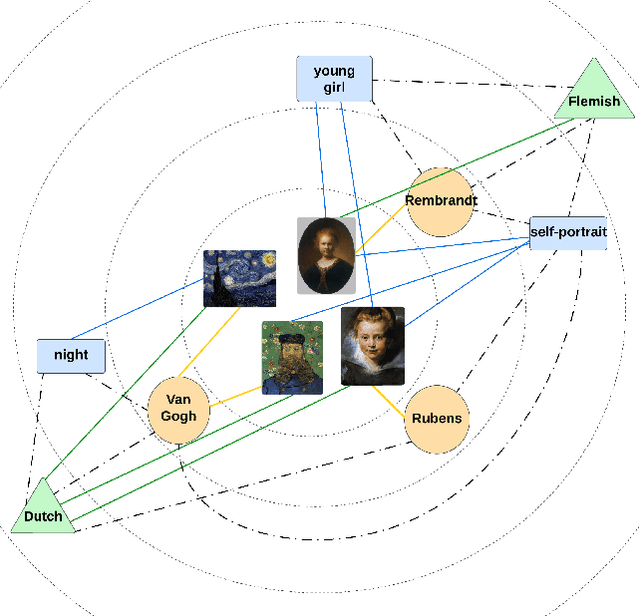
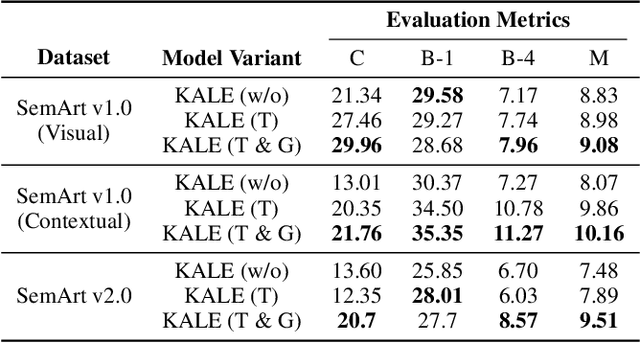
Exploring the narratives conveyed by fine-art paintings is a challenge in image captioning, where the goal is to generate descriptions that not only precisely represent the visual content but also offer a in-depth interpretation of the artwork's meaning. The task is particularly complex for artwork images due to their diverse interpretations and varied aesthetic principles across different artistic schools and styles. In response to this, we present KALE Knowledge-Augmented vision-Language model for artwork Elaborations), a novel approach that enhances existing vision-language models by integrating artwork metadata as additional knowledge. KALE incorporates the metadata in two ways: firstly as direct textual input, and secondly through a multimodal heterogeneous knowledge graph. To optimize the learning of graph representations, we introduce a new cross-modal alignment loss that maximizes the similarity between the image and its corresponding metadata. Experimental results demonstrate that KALE achieves strong performance (when evaluated with CIDEr, in particular) over existing state-of-the-art work across several artwork datasets. Source code of the project is available at https://github.com/Yanbei-Jiang/Artwork-Interpretation.