 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closed-Loop Multi-perspective Visual Servoing Approach with Reinforcement Learning
Paper and Code
Dec 25, 2023
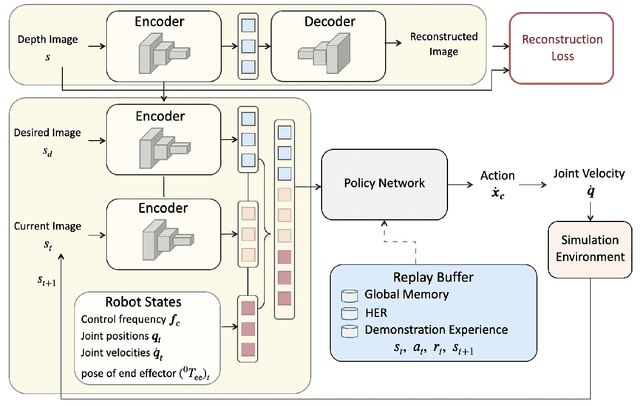
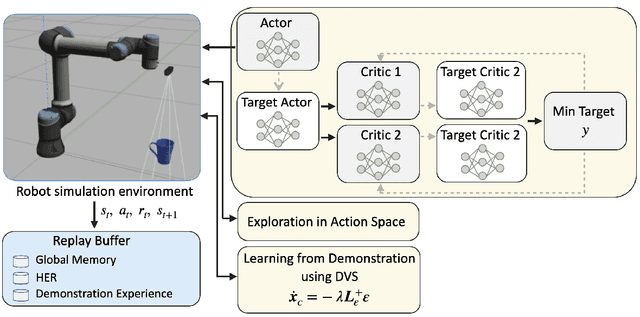
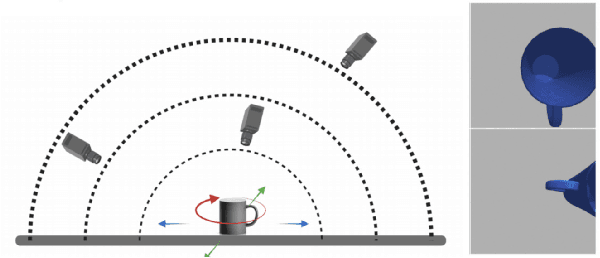
Traditional visual servoing methods suffer from serving between scenes from multiple perspectives, which humans can complete with visual signals alone. In this paper, we investigated how multi-perspective visual servoing could be solved under robot-specific constraints, including self-collision, singularity problems. We presented a novel learning-based multi-perspective visual servoing framework, which iteratively estimates robot actions from latent space representations of visual states using reinforcement learning. Furthermore, our approaches were trained and validated in a Gazebo simulation environment with connection to OpenAI/Gym. Through simulation experiments, we showed that our method can successfully learn an optimal control policy given initial images from different perspectives, and it outperformed the Direct Visual Servoing algorithm with mean success rate of 97.0%.