 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAFLO: GPU-Based Acceleration for Federated Logistic Regression
Aug 22, 2021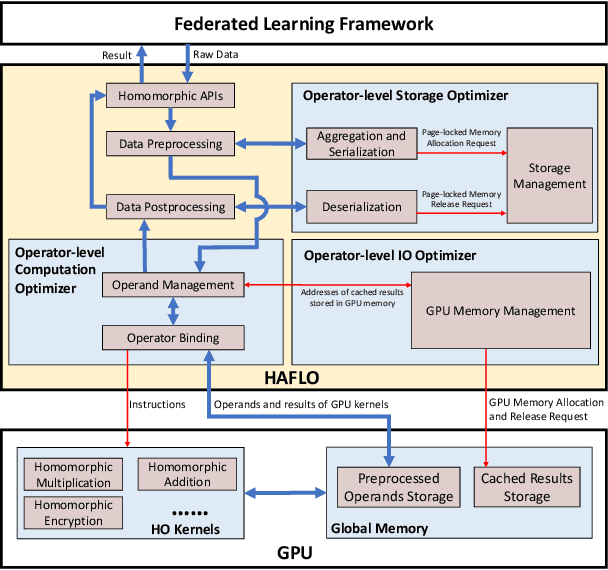

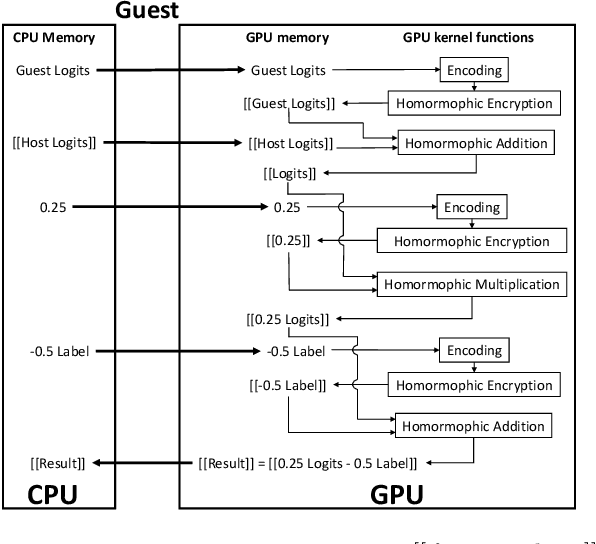

In recent years, federated learning (FL) has been widely applied for supporting decentralized collaborative learning scenarios. Among existing FL models, federated logistic regression (FLR) is a widely used statistic model and has been used in various industries. To ensure data security and user privacy, FLR leverages homomorphic encryption (HE) to protect the exchanged data among different collaborative parties. However, HE introduces significant computational overhead (i.e., the cost of data encryption/decryption and calculation over encrypted data), which eventually becomes the performance bottleneck of the whole system. In this paper, we propose HAFLO, a GPU-based solution to improve the performance of FLR. The core idea of HAFLO is to summarize a set of performance-critical homomorphic operators (HO) used by FLR and accelerate the execution of these operators through a joint optimization of storage, IO, and computation. The preliminary results show that our acceleration on FATE, a popular FL framework, achieves a 49.9$\times$ speedup for heterogeneous LR and 88.4$\times$ for homogeneous LR.
FPGA-Based Hardware Accelerator of Homomorphic Encryption for Efficient Federated Learning
Jul 21, 2020

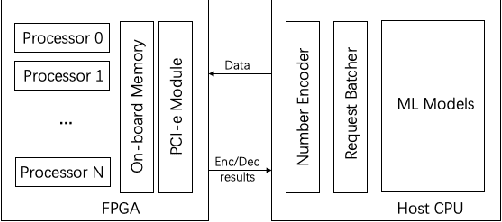
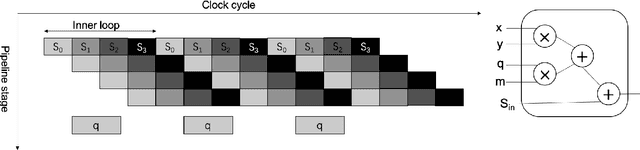
With the increasing awareness of privacy protection and data fragmentation problem, federated learning has been emerging as a new paradigm of machine learning. Federated learning tends to utilize various privacy preserving mechanisms to protect the transferred intermediate data, among which homomorphic encryption strikes a balance between security and ease of utilization. However, the complicated operations and large operands impose significant overhead on federated learning. Maintaining accuracy and security more efficiently has been a key problem of federated learning. In this work, we investigate a hardware solution, and design an FPGA-based homomorphic encryption framework, aiming to accelerate the training phase in federated learning. The root complexity lies in searching for a compact architecture for the core operation of homomorphic encryption, to suit the requirement of federated learning about high encryption throughput and flexibility of configuration. Our framework implements the representative Paillier homomorphic cryptosystem with high level synthesis for flexibility and portability, with careful optimization on the modular multiplication operation in terms of processing clock cycle, resource usage and clock frequency. Our accelerator achieves a near-optimal execution clock cycle, with a better DSP-efficiency than existing designs, and reduces the encryption time by up to 71% during training process of various federated learning models.