 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive scale-invariant online algorithms for learning linear models
Feb 20, 2019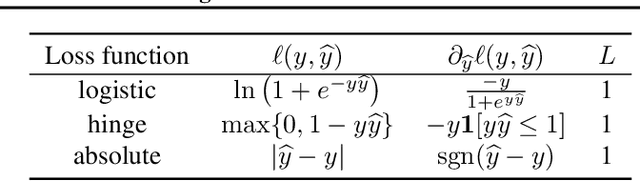
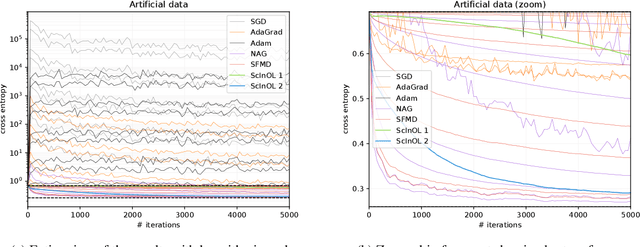
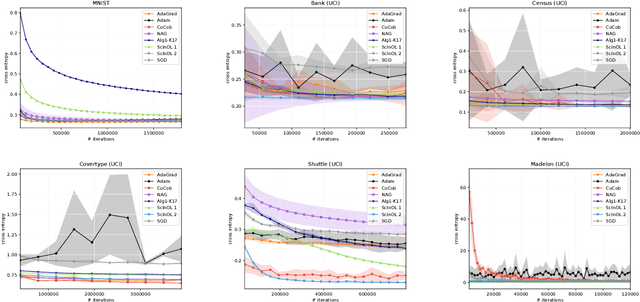
We consider online learning with linear models, where the algorithm predicts on sequentially revealed instances (feature vectors), and is compared against the best linear function (comparator) in hindsight. Popular algorithms in this framework, such as Online Gradient Descent (OGD), have parameters (learning rates), which ideally should be tuned based on the scales of the features and the optimal comparator, but these quantities only become available at the end of the learning process. In this paper, we resolve the tuning problem by proposing online algorithms making predictions which are invariant under arbitrary rescaling of the features. The algorithms have no parameters to tune, do not require any prior knowledge on the scale of the instances or the comparator, and achieve regret bounds matching (up to a logarithmic factor) that of OGD with optimally tuned separate learning rates per dimension, while retaining comparable runtime performance.
ViZDoom Competitions: Playing Doom from Pixels
Sep 10, 2018



This paper presents the first two editions of Visual Doom AI Competition, held in 2016 and 2017. The challenge was to create bots that compete in a multi-player deathmatch in a first-person shooter (FPS) game, Doom. The bots had to make their decisions based solely on visual information, i.e., a raw screen buffer. To play well, the bots needed to understand their surroundings, navigate, explore, and handle the opponents at the same time. These aspects, together with the competitive multi-agent aspect of the game, make the competition a unique platform for evaluating the state of the art reinforcement learning algorithms. The paper discusses the rules, solutions, results, and statistics that give insight into the agents' behaviors. Best-performing agents are described in more detail. The results of the competition lead to the conclusion that, although reinforcement learning can produce capable Doom bots, they still are not yet able to successfully compete against humans in this game. The paper also revisits the ViZDoom environment, which is a flexible, easy to use, and efficient 3D platform for research for vision-based reinforcement learning, based on a well-recognized first-person perspective game Doom.
ViZDoom: A Doom-based AI Research Platform for Visual Reinforcement Learning
Sep 20, 2016


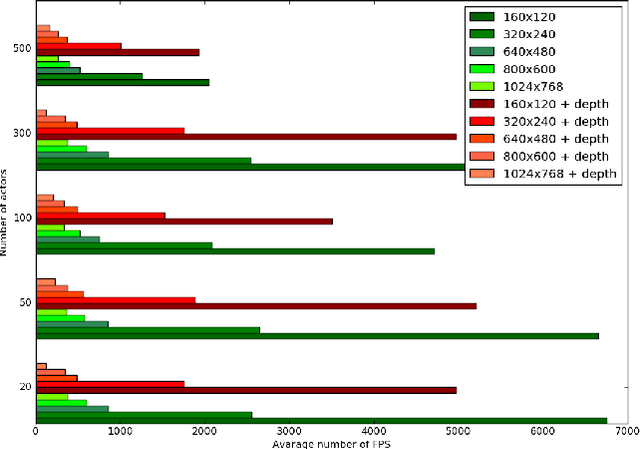
The recent advances in deep neural networks have led to effective vision-based reinforcement learning methods that have been employed to obtain human-level controllers in Atari 2600 games from pixel data. Atari 2600 games, however, do not resemble real-world tasks since they involve non-realistic 2D environments and the third-person perspective. Here, we propose a novel test-bed platform for reinforcement learning research from raw visual information which employs the first-person perspective in a semi-realistic 3D world. The software, called ViZDoom, is based on the classical first-person shooter video game, Doom. It allows developing bots that play the game using the screen buffer. ViZDoom is lightweight, fast, and highly customizable via a convenient mechanism of user scenarios. In the experimental part, we test the environment by trying to learn bots for two scenarios: a basic move-and-shoot task and a more complex maze-navigation problem. Using convolutional deep neural networks with Q-learning and experience replay, for both scenarios, we were able to train competent bots, which exhibit human-like behaviors. The results confirm the utility of ViZDoom as an AI research platform and imply that visual reinforcement learning in 3D realistic first-person perspective environments is feasible.