 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsumer Transactions Simulation through Generative Adversarial Networks
Aug 07, 2024In the rapidly evolving domain of large-scale retail data systems, envisioning and simulating future consumer transactions has become a crucial area of interest. It offers significant potential to fortify demand forecasting and fine-tune inventory management. This paper presents an innovative application of Generative Adversarial Networks (GANs) to generate synthetic retail transaction data, specifically focusing on a novel system architecture that combines consumer behavior modeling with stock-keeping unit (SKU) availability constraints to address real-world assortment optimization challenges. We diverge from conventional methodologies by integrating SKU data into our GAN architecture and using more sophisticated embedding methods (e.g., hyper-graphs). This design choice enables our system to generate not only simulated consumer purchase behaviors but also reflects the dynamic interplay between consumer behavior and SKU availability -- an aspect often overlooked, among others, because of data scarcity in legacy retail simulation models. Our GAN model generates transactions under stock constraints, pioneering a resourceful experimental system with practical implications for real-world retail operation and strategy. Preliminary results demonstrate enhanced realism in simulated transactions measured by comparing generated items with real ones using methods employed earlier in related studies. This underscores the potential for more accurate predictive modeling.
Identifying Substitute and Complementary Products for Assortment Optimization with Cleora Embeddings
Aug 10, 2022


Recent years brought an increasing interest in the application of machine learning algorithms in e-commerce, omnichannel marketing, and the sales industry. It is not only to the algorithmic advances but also to data availability, representing transactions, users, and background product information. Finding products related in different ways, i.e., substitutes and complements is essential for users' recommendations at the vendor's site and for the vendor - to perform efficient assortment optimization. The paper introduces a novel method for finding products' substitutes and complements based on the graph embedding Cleora algorithm. We also provide its experimental evaluation with regards to the state-of-the-art Shopper algorithm, studying the relevance of recommendations with surveys from industry experts. It is concluded that the new approach presented here offers suitable choices of recommended products, requiring a minimal amount of additional information. The algorithm can be used in various enterprises, effectively identifying substitute and complementary product options.
Multilingual Transformers for Product Matching -- Experiments and a New Benchmark in Polish
Jun 01, 2022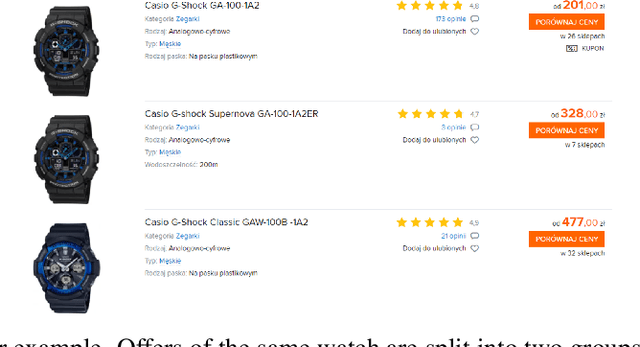

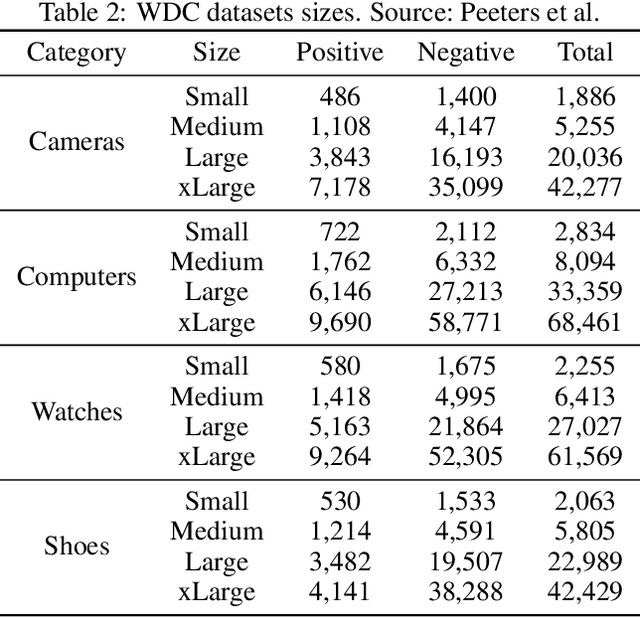
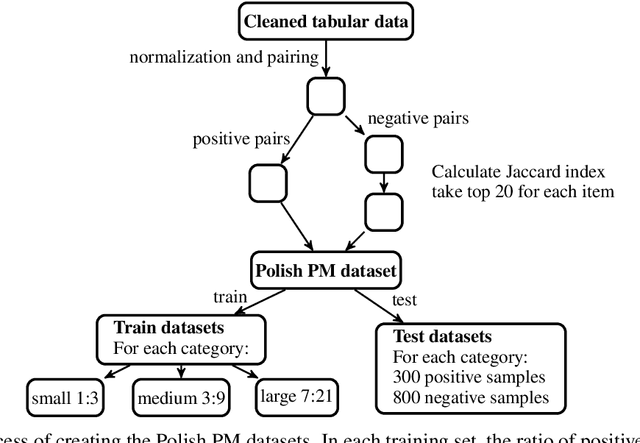
Product matching corresponds to the task of matching identical products across different data sources. It typically employs available product features which, apart from being multimodal, i.e., comprised of various data types, might be non-homogeneous and incomplete. The paper shows that pre-trained, multilingual Transformer models, after fine-tuning, are suitable for solving the product matching problem using textual features both in English and Polish languages. We tested multilingual mBERT and XLM-RoBERTa models in English on Web Data Commons - training dataset and gold standard for large-scale product matching. The obtained results show that these models perform similarly to the latest solutions tested on this set, and in some cases, the results were even better. Additionally, we prepared a new dataset entirely in Polish and based on offers in selected categories obtained from several online stores for the research purpose. It is the first open dataset for product matching tasks in Polish, which allows comparing the effectiveness of the pre-trained models. Thus, we also showed the baseline results obtained by the fine-tuned mBERT and XLM-RoBERTa models on the Polish datasets.