 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Text Mining to Analyze Human Question Asking in Creativity Research
Jan 03, 2025
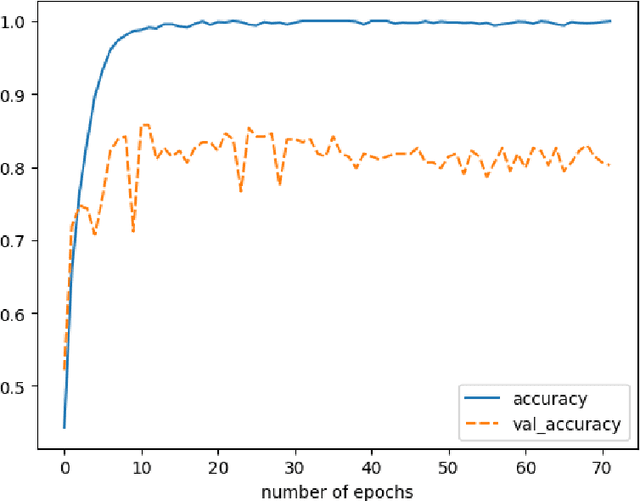


Creativity relates to the ability to generate novel and effective ideas in the areas of interest. How are such creative ideas generated? One possible mechanism that supports creative ideation and is gaining increased empirical attention is by asking questions. Question asking is a likely cognitive mechanism that allows defining problems, facilitating creative problem solving. However, much is unknown about the exact role of questions in creativity. This work presents an attempt to apply text mining methods to measure the cognitive potential of questions, taking into account, among others, (a) question type, (b) question complexity, and (c) the content of the answer. This contribution summarizes the history of question mining as a part of creativity research, along with the natural language processing methods deemed useful or helpful in the study. In addition, a novel approach is proposed, implemented, and applied to five datasets. The experimental results obtained are comprehensively analyzed, suggesting that natural language processing has a role to play in creative research.
Adaptive Active Inference Agents for Heterogeneous and Lifelong Federated Learning
Oct 09, 2024Handling heterogeneity and unpredictability are two core problems in pervasive computing. The challenge is to seamlessly integrate devices with varying computational resources in a dynamic environment to form a cohesive system that can fulfill the needs of all participants. Existing work on systems that adapt to changing requirements typically focuses on optimizing individual variables or low-level Service Level Objectives (SLOs), such as constraining the usage of specific resources. While low-level control mechanisms permit fine-grained control over a system, they introduce considerable complexity, particularly in dynamic environments. To this end, we propose drawing from Active Inference (AIF), a neuroscientific framework for designing adaptive agents. Specifically, we introduce a conceptual agent for heterogeneous pervasive systems that permits setting global systems constraints as high-level SLOs. Instead of manually setting low-level SLOs, the system finds an equilibrium that can adapt to environmental changes. We demonstrate the viability of AIF agents with an extensive experiment design, using heterogeneous and lifelong federated learning as an application scenario. We conduct our experiments on a physical testbed of devices with different resource types and vendor specifications. The results provide convincing evidence that an AIF agent can adapt a system to environmental changes. In particular, the AIF agent can balance competing SLOs in resource heterogeneous environments to ensure up to 98% fulfillment rate.
Fake News Detection: It's All in the Data!
Jul 02, 2024This comprehensive survey serves as an indispensable resource for researchers embarking on the journey of fake news detection. By highlighting the pivotal role of dataset quality and diversity, it underscores the significance of these elements in the effectiveness and robustness of detection models. The survey meticulously outlines the key features of datasets, various labeling systems employed, and prevalent biases that can impact model performance. Additionally, it addresses critical ethical issues and best practices, offering a thorough overview of the current state of available datasets. Our contribution to this field is further enriched by the provision of GitHub repository, which consolidates publicly accessible datasets into a single, user-friendly portal. This repository is designed to facilitate and stimulate further research and development efforts aimed at combating the pervasive issue of fake news.
RDF Stream Taxonomy: Systematizing RDF Stream Types in Research and Practice
Dec 07, 2023Over the years, RDF streaming was explored in research and practice from many angles, resulting in a wide range of RDF stream definitions. This variety presents a major challenge in discussing and integrating streaming solutions, due to the lack of a common language. This work attempts to address this critical research gap, by systematizing RDF stream types present in the literature in a novel taxonomy. The proposed RDF Stream Taxonomy (RDF-STaX) is embodied in an OWL 2 DL ontology that follows the FAIR principles, making it readily applicable in practice. Extensive documentation and additional resources are provided, to foster the adoption of the ontology. Two realized use cases are presented, demonstrating the usefulness of the resource in discussing research works and annotating streaming datasets. Another result of this contribution is the novel nanopublications dataset, which serves as a collaborative, living state-of-the-art review of RDF streaming. The aim of RDF-STaX is to address a real need of the community for a better way to systematize and describe RDF streams. The resource is designed to help drive innovation in RDF streaming, by fostering scientific discussion, cooperation, and tool interoperability.
Enriching language models with graph-based context information to better understand textual data
May 10, 2023A considerable number of texts encountered daily are somehow connected with each other. For example, Wikipedia articles refer to other articles via hyperlinks, scientific papers relate to others via citations or (co)authors, while tweets relate via users that follow each other or reshare content. Hence, a graph-like structure can represent existing connections and be seen as capturing the "context" of the texts. The question thus arises if extracting and integrating such context information into a language model might help facilitate a better automated understanding of the text. In this study, we experimentally demonstrate that incorporating graph-based contextualization into BERT model enhances its performance on an example of a classification task. Specifically, on Pubmed dataset, we observed a reduction in error from 8.51% to 7.96%, while increasing the number of parameters just by 1.6%. Our source code: https://github.com/tryptofanik/gc-bert
Towards Edge-Cloud Architectures for Personal Protective Equipment Detection
Jan 04, 2023Detecting Personal Protective Equipment in images and video streams is a relevant problem in ensuring the safety of construction workers. In this contribution, an architecture enabling live image recognition of such equipment is proposed. The solution is deployable in two settings -- edge-cloud and edge-only. The system was tested on an active construction site, as a part of a larger scenario, within the scope of the ASSIST-IoT H2020 project. To determine the feasibility of the edge-only variant, a model for counting people wearing safety helmets was developed using the YOLOX method. It was found that an edge-only deployment is possible for this use case, given the hardware infrastructure available on site. In the preliminary evaluation, several important observations were made, that are crucial to the further development and deployment of the system. Future work will include an in-depth investigation of performance aspects of the two architecture variants.
Introducing Federated Learning into Internet of Things ecosystems -- preliminary considerations
Jul 15, 2022
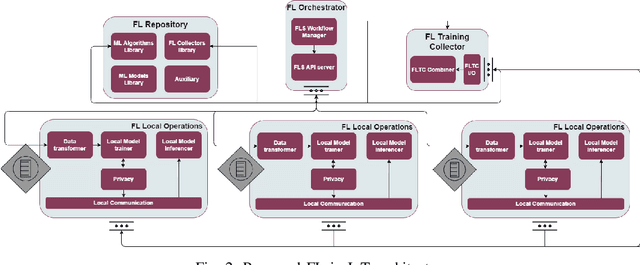
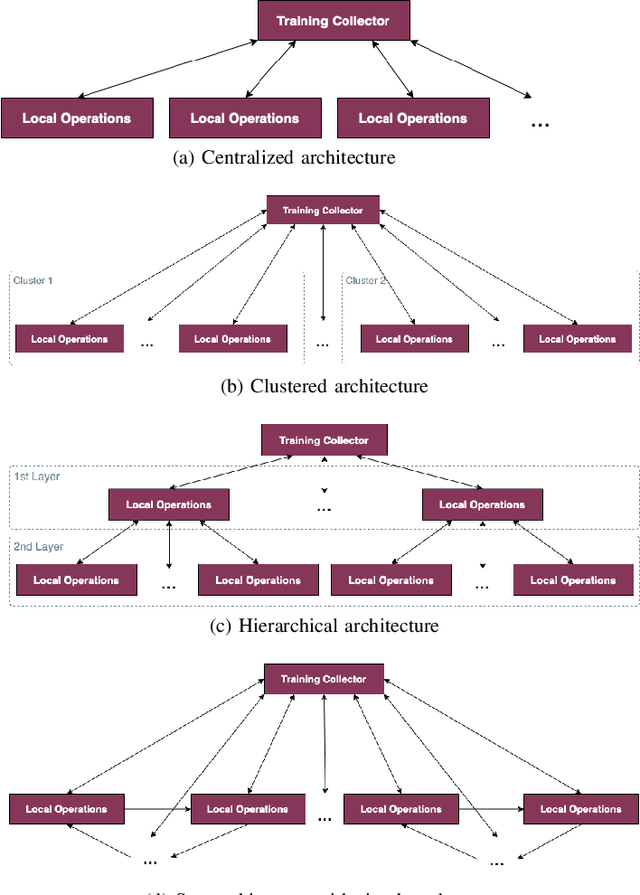
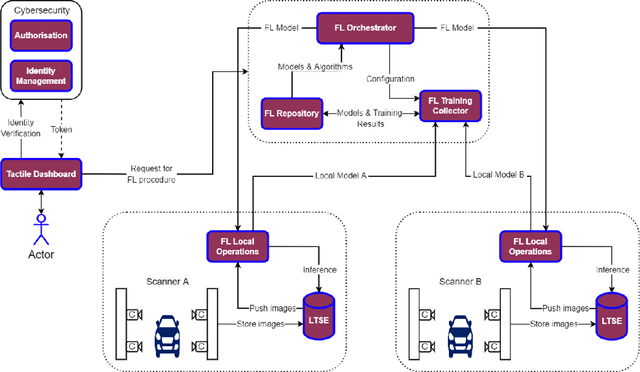
Federated learning (FL) was proposed to facilitate the training of models in a distributed environment. It supports the protection of (local) data privacy and uses local resources for model training. Until now, the majority of research has been devoted to "core issues", such as adaptation of machine learning algorithms to FL, data privacy protection, or dealing with the effects of uneven data distribution between clients. This contribution is anchored in a practical use case, where FL is to be actually deployed within an Internet of Things ecosystem. Hence, somewhat different issues that need to be considered, beyond popular considerations found in the literature, are identified. Moreover, an architecture that enables the building of flexible, and adaptable, FL solutions is introduced.
StatMix: Data augmentation method that relies on image statistics in federated learning
Jul 08, 2022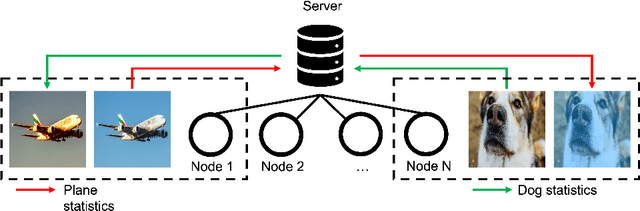
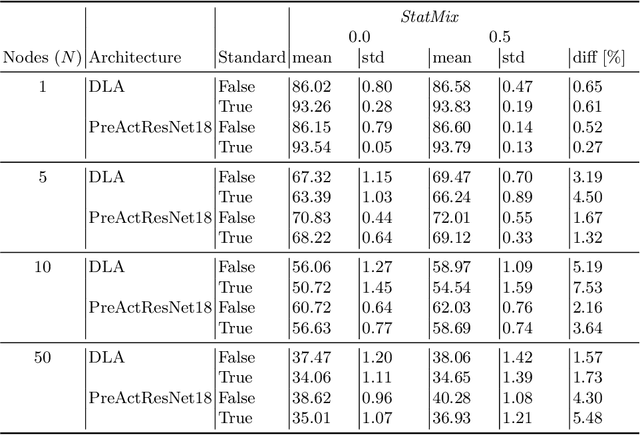

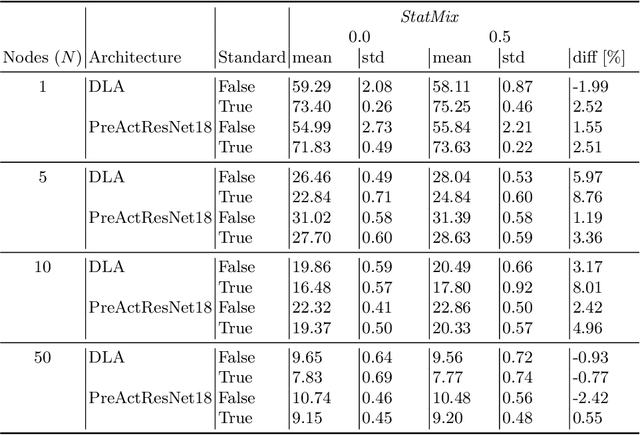
Availability of large amount of annotated data is one of the pillars of deep learning success. Although numerous big datasets have been made available for research, this is often not the case in real life applications (e.g. companies are not able to share data due to GDPR or concerns related to intellectual property rights protection). Federated learning (FL) is a potential solution to this problem, as it enables training a global model on data scattered across multiple nodes, without sharing local data itself. However, even FL methods pose a threat to data privacy, if not handled properly. Therefore, we propose StatMix, an augmentation approach that uses image statistics, to improve results of FL scenario(s). StatMix is empirically tested on CIFAR-10 and CIFAR-100, using two neural network architectures. In all FL experiments, application of StatMix improves the average accuracy, compared to the baseline training (with no use of StatMix). Some improvement can also be observed in non-FL setups.
Using adversarial images to improve outcomes of federated learning for non-IID data
Jun 16, 2022

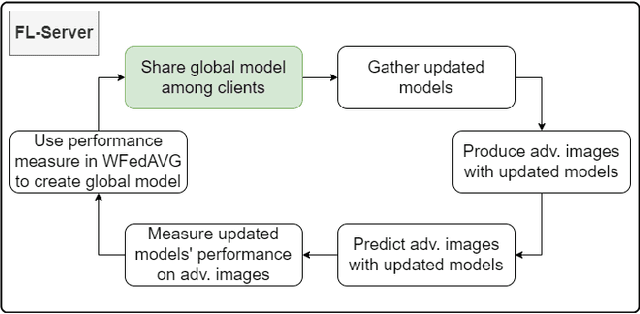
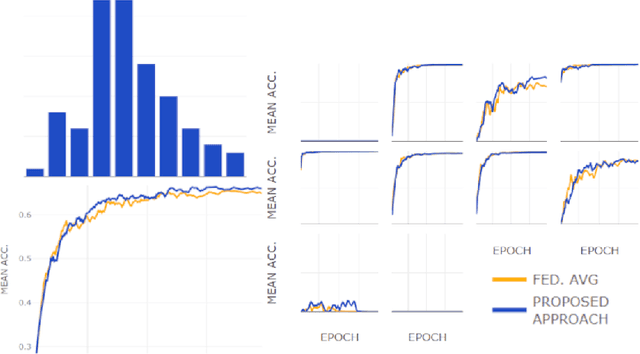
One of the important problems in federated learning is how to deal with unbalanced data. This contribution introduces a novel technique designed to deal with label skewed non-IID data, using adversarial inputs, created by the I-FGSM method. Adversarial inputs guide the training process and allow the Weighted Federated Averaging to give more importance to clients with 'selected' local label distributions. Experimental results, gathered from image classification tasks, for MNIST and CIFAR-10 datasets, are reported and analyzed.
Ontology Reuse: the Real Test of Ontological Design
May 05, 2022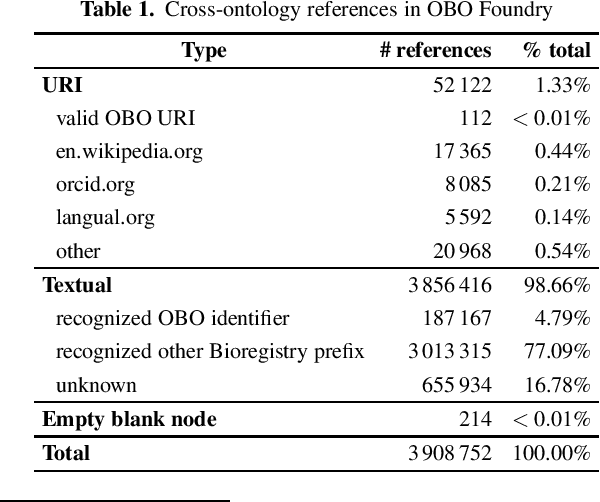
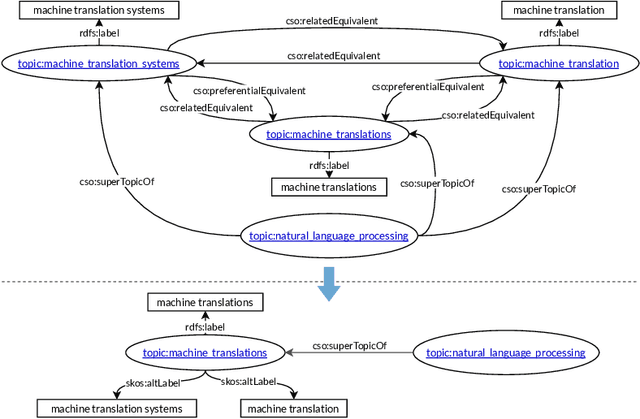

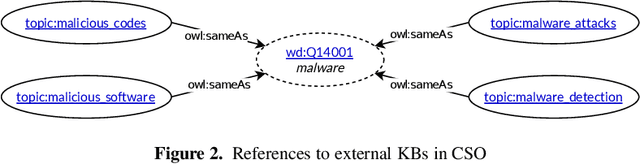
Reusing ontologies in practice is still very challenging, especially when multiple ontologies are involved. Moreover, despite recent advances, systematic ontology quality assurance remains a difficult problem. In this work, the quality of thirty biomedical ontologies, and the Computer Science Ontology, are investigated from the perspective of a practical use case. Special scrutiny is given to cross-ontology references, which are vital for combining ontologies. Diverse methods to detect the issues are proposed, including natural language processing and network analysis. Moreover, several suggestions for improving ontologies and their quality assurance processes are presented. It is argued that while the advancing automatic tools for ontology quality assurance are crucial for ontology improvement, they will not solve the problem entirely. It is ontology reuse that is the ultimate method for continuously verifying and improving ontology quality, as well as for guiding its future development. Many issues can be found and fixed only through practical and diverse ontology reuse scenarios.