 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentionMix: Data augmentation method that relies on BERT attention mechanism
Sep 20, 2023



The Mixup method has proven to be a powerful data augmentation technique in Computer Vision, with many successors that perform image mixing in a guided manner. One of the interesting research directions is transferring the underlying Mixup idea to other domains, e.g. Natural Language Processing (NLP). Even though there already exist several methods that apply Mixup to textual data, there is still room for new, improved approaches. In this work, we introduce AttentionMix, a novel mixing method that relies on attention-based information. While the paper focuses on the BERT attention mechanism, the proposed approach can be applied to generally any attention-based model. AttentionMix is evaluated on 3 standard sentiment classification datasets and in all three cases outperforms two benchmark approaches that utilize Mixup mechanism, as well as the vanilla BERT method. The results confirm that the attention-based information can be effectively used for data augmentation in the NLP domain.
StatMix: Data augmentation method that relies on image statistics in federated learning
Jul 08, 2022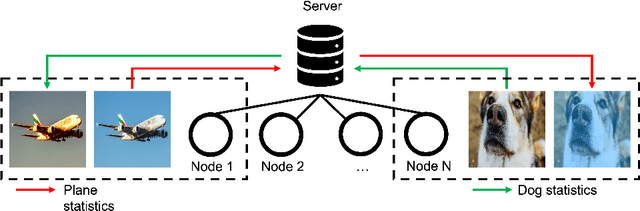
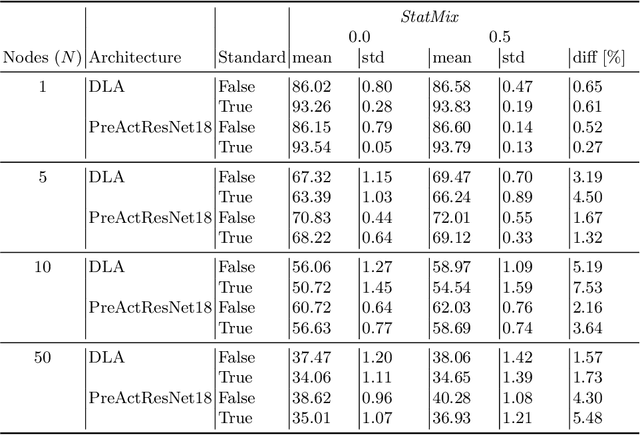

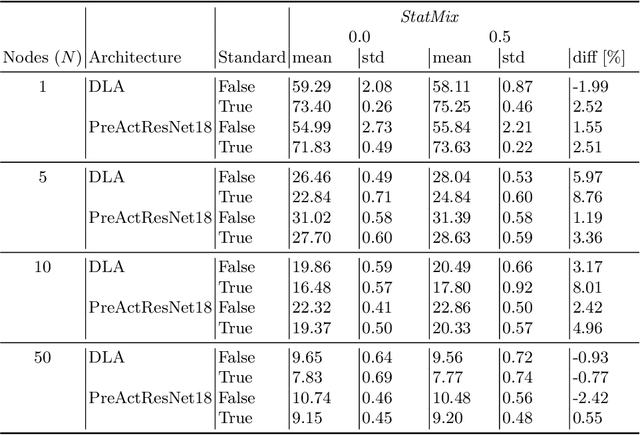
Availability of large amount of annotated data is one of the pillars of deep learning success. Although numerous big datasets have been made available for research, this is often not the case in real life applications (e.g. companies are not able to share data due to GDPR or concerns related to intellectual property rights protection). Federated learning (FL) is a potential solution to this problem, as it enables training a global model on data scattered across multiple nodes, without sharing local data itself. However, even FL methods pose a threat to data privacy, if not handled properly. Therefore, we propose StatMix, an augmentation approach that uses image statistics, to improve results of FL scenario(s). StatMix is empirically tested on CIFAR-10 and CIFAR-100, using two neural network architectures. In all FL experiments, application of StatMix improves the average accuracy, compared to the baseline training (with no use of StatMix). Some improvement can also be observed in non-FL setups.
An overview of mixing augmentation methods and augmentation strategies
Jul 21, 2021



Deep Convolutional Neural Networks have made an incredible progress in many Computer Vision tasks. This progress, however, often relies on the availability of large amounts of the training data, required to prevent over-fitting, which in many domains entails significant cost of manual data labeling. An alternative approach is application of data augmentation (DA) techniques that aim at model regularization by creating additional observations from the available ones. This survey focuses on two DA research streams: image mixing and automated selection of augmentation strategies. First, the presented methods are briefly described, and then qualitatively compared with respect to their key characteristics. Various quantitative comparisons are also included based on the results reported in recent DA literature. This review mainly covers the methods published in the materials of top-tier conferences and in leading journals in the years 2017-2021.