 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing Federated Learning into Internet of Things ecosystems -- preliminary considerations
Jul 15, 2022
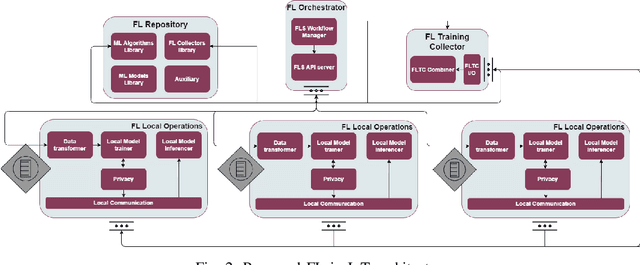
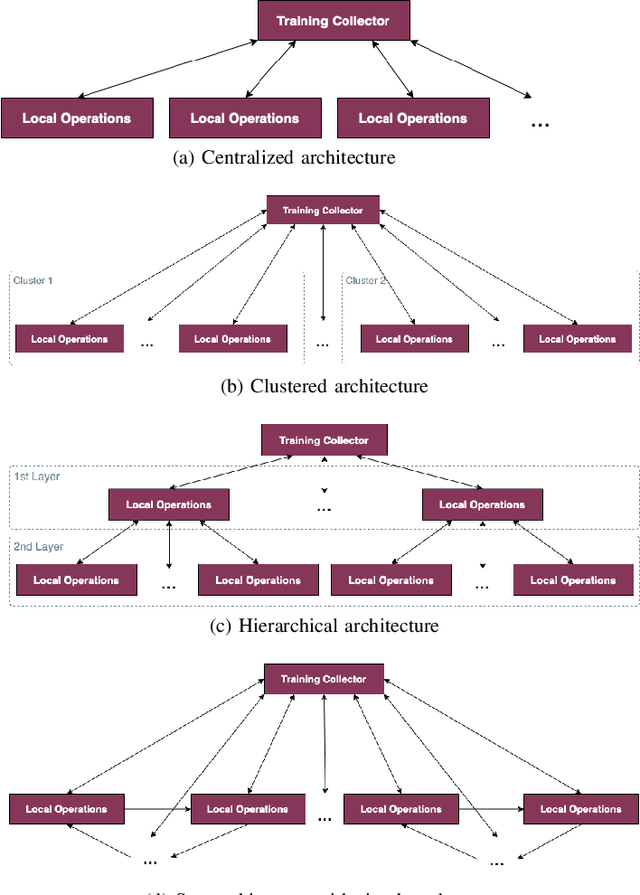
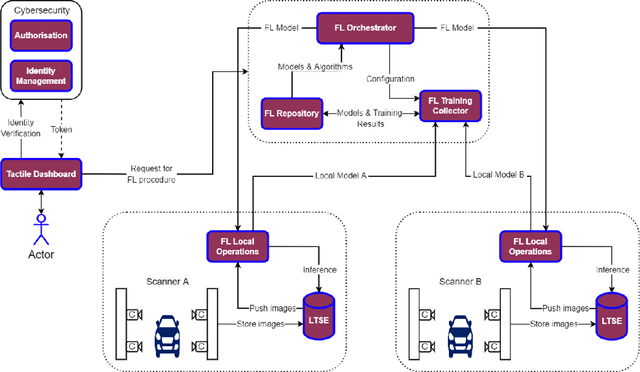
Federated learning (FL) was proposed to facilitate the training of models in a distributed environment. It supports the protection of (local) data privacy and uses local resources for model training. Until now, the majority of research has been devoted to "core issues", such as adaptation of machine learning algorithms to FL, data privacy protection, or dealing with the effects of uneven data distribution between clients. This contribution is anchored in a practical use case, where FL is to be actually deployed within an Internet of Things ecosystem. Hence, somewhat different issues that need to be considered, beyond popular considerations found in the literature, are identified. Moreover, an architecture that enables the building of flexible, and adaptable, FL solutions is introduced.
Ontology Reuse: the Real Test of Ontological Design
May 05, 2022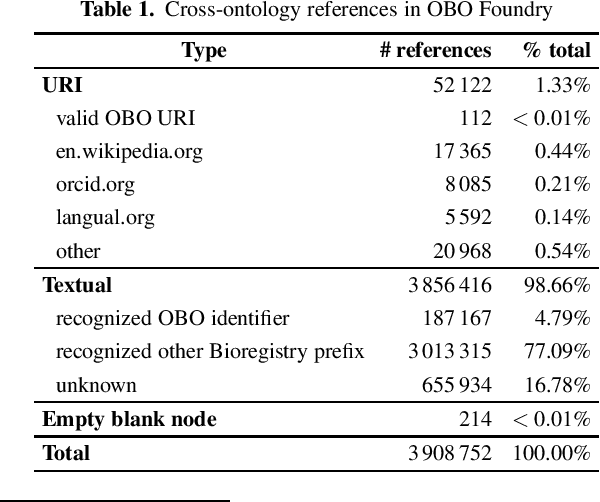
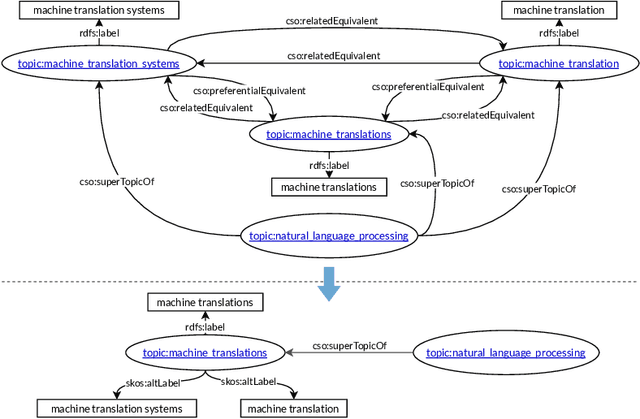

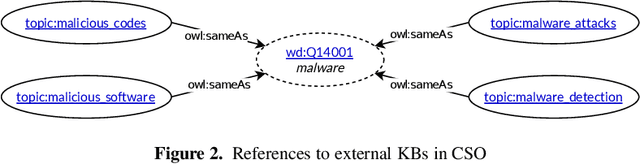
Reusing ontologies in practice is still very challenging, especially when multiple ontologies are involved. Moreover, despite recent advances, systematic ontology quality assurance remains a difficult problem. In this work, the quality of thirty biomedical ontologies, and the Computer Science Ontology, are investigated from the perspective of a practical use case. Special scrutiny is given to cross-ontology references, which are vital for combining ontologies. Diverse methods to detect the issues are proposed, including natural language processing and network analysis. Moreover, several suggestions for improving ontologies and their quality assurance processes are presented. It is argued that while the advancing automatic tools for ontology quality assurance are crucial for ontology improvement, they will not solve the problem entirely. It is ontology reuse that is the ultimate method for continuously verifying and improving ontology quality, as well as for guiding its future development. Many issues can be found and fixed only through practical and diverse ontology reuse scenarios.
Topical Classification of Food Safety Publications with a Knowledge Base
Jan 04, 2022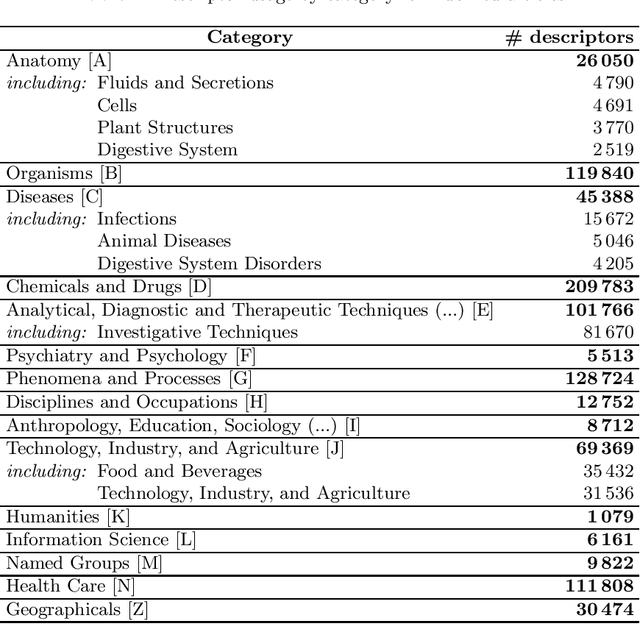
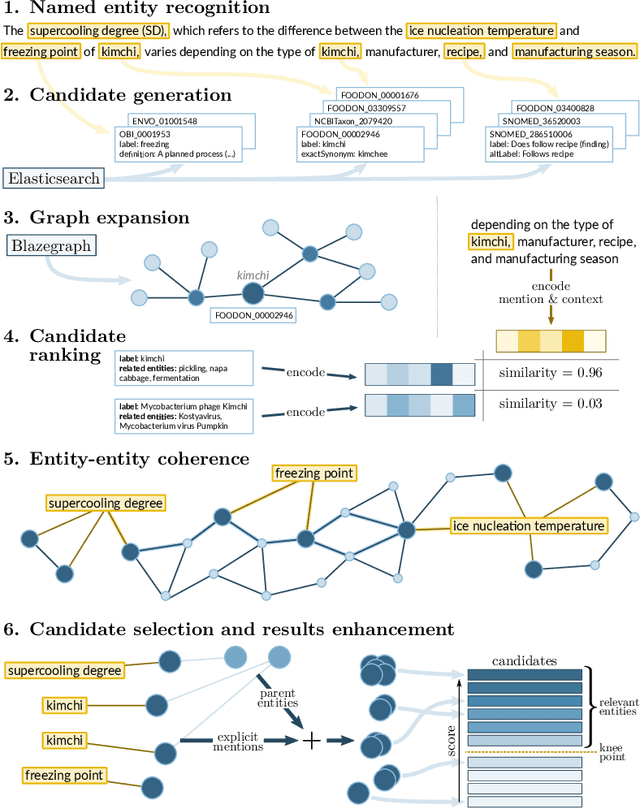
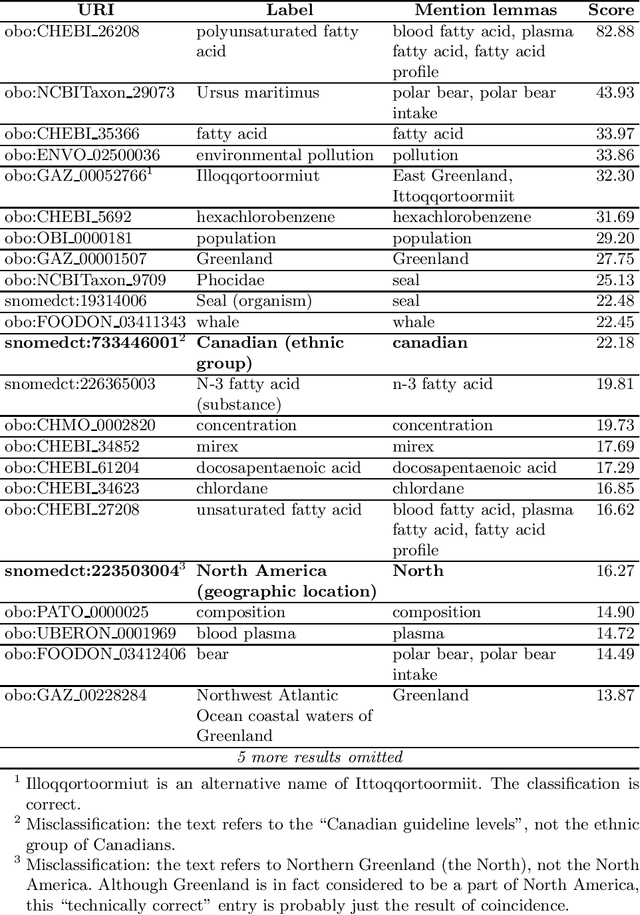
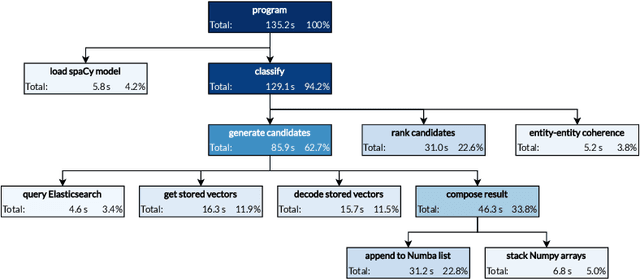
The vast body of scientific publications presents an increasing challenge of finding those that are relevant to a given research question, and making informed decisions on their basis. This becomes extremely difficult without the use of automated tools. Here, one possible area for improvement is automatic classification of publication abstracts according to their topic. This work introduces a novel, knowledge base-oriented publication classifier. The proposed method focuses on achieving scalability and easy adaptability to other domains. Classification speed and accuracy are shown to be satisfactory, in the very demanding field of food safety. Further development and evaluation of the method is needed, as the proposed approach shows much potential.