 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolish Natural Language Inference and Factivity -- an Expert-based Dataset and Benchmarks
Jan 10, 2022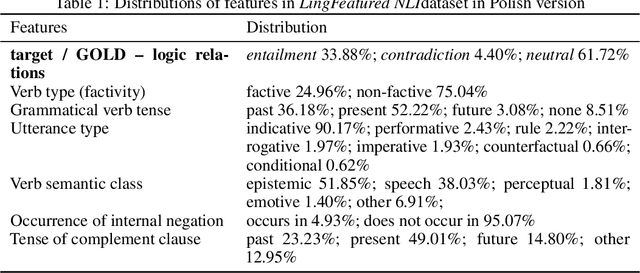

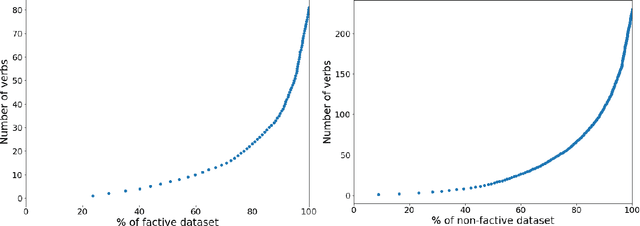
Despite recent breakthroughs in Machine Learning for Natural Language Processing, the Natural Language Inference (NLI) problems still constitute a challenge. To this purpose we contribute a new dataset that focuses exclusively on the factivity phenomenon; however, our task remains the same as other NLI tasks, i.e. prediction of entailment, contradiction or neutral (ECN). The dataset contains entirely natural language utterances in Polish and gathers 2,432 verb-complement pairs and 309 unique verbs. The dataset is based on the National Corpus of Polish (NKJP) and is a representative sample in regards to frequency of main verbs and other linguistic features (e.g. occurrence of internal negation). We found that transformer BERT-based models working on sentences obtained relatively good results ($\approx89\%$ F1 score). Even though better results were achieved using linguistic features ($\approx91\%$ F1 score), this model requires more human labour (humans in the loop) because features were prepared manually by expert linguists. BERT-based models consuming only the input sentences show that they capture most of the complexity of NLI/factivity. Complex cases in the phenomenon - e.g. cases with entitlement (E) and non-factive verbs - remain an open issue for further research.
Named Entity Recognition -- Is there a glass ceiling?
Oct 30, 2019

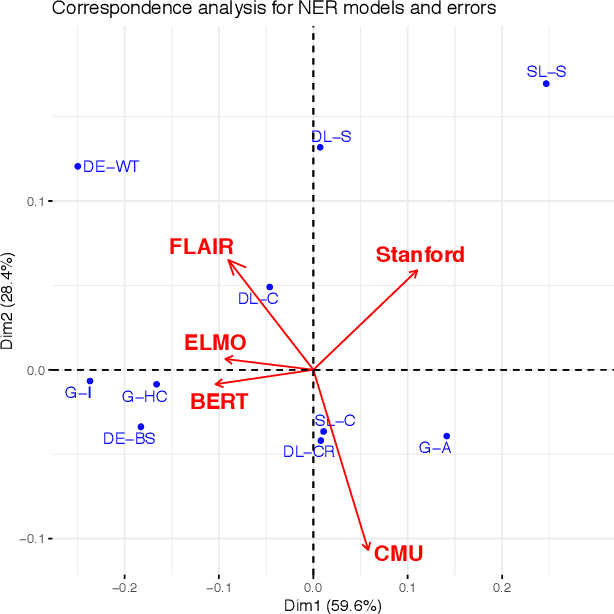
Recent developments in Named Entity Recognition (NER) have resulted in better and better models. However, is there a glass ceiling? Do we know which types of errors are still hard or even impossible to correct? In this paper, we present a detailed analysis of the types of errors in state-of-the-art machine learning (ML) methods. Our study reveals the weak and strong points of the Stanford, CMU, FLAIR, ELMO and BERT models, as well as their shared limitations. We also introduce new techniques for improving annotation, for training processes and for checking a model's quality and stability. Presented results are based on the CoNLL 2003 data set for the English language. A new enriched semantic annotation of errors for this data set and new diagnostic data sets are attached in the supplementary materials.