 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCase -- Rethinking Casing in Language Models
Oct 22, 2020

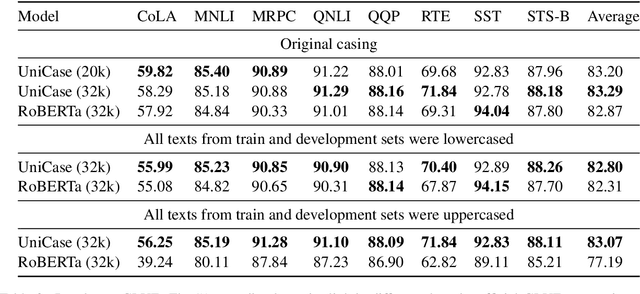
In this paper, we introduce a new approach to dealing with the problem of case-sensitiveness in Language Modelling (LM). We propose simple architecture modification to the RoBERTa language model, accompanied by a new tokenization strategy, which we named Unified Case LM (UniCase). We tested our solution on the GLUE benchmark, which led to increased performance by 0.42 points. Moreover, we prove that the UniCase model works much better when we have to deal with text data, where all tokens are uppercased (+5.88 point).
Named Entity Recognition -- Is there a glass ceiling?
Oct 30, 2019

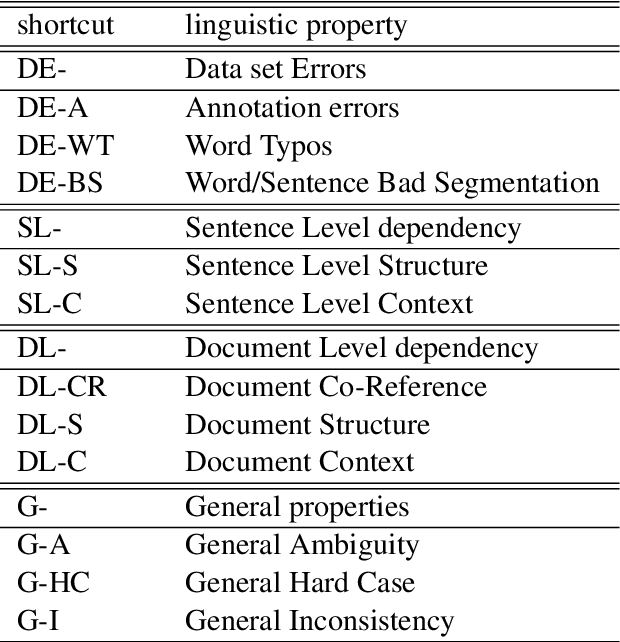
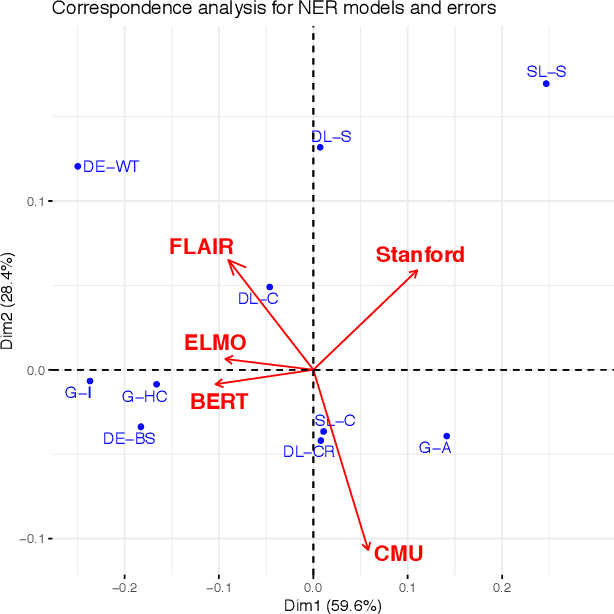
Recent developments in Named Entity Recognition (NER) have resulted in better and better models. However, is there a glass ceiling? Do we know which types of errors are still hard or even impossible to correct? In this paper, we present a detailed analysis of the types of errors in state-of-the-art machine learning (ML) methods. Our study reveals the weak and strong points of the Stanford, CMU, FLAIR, ELMO and BERT models, as well as their shared limitations. We also introduce new techniques for improving annotation, for training processes and for checking a model's quality and stability. Presented results are based on the CoNLL 2003 data set for the English language. A new enriched semantic annotation of errors for this data set and new diagnostic data sets are attached in the supplementary materials.