Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCase -- Rethinking Casing in Language Models
Paper and Code
Oct 22, 2020

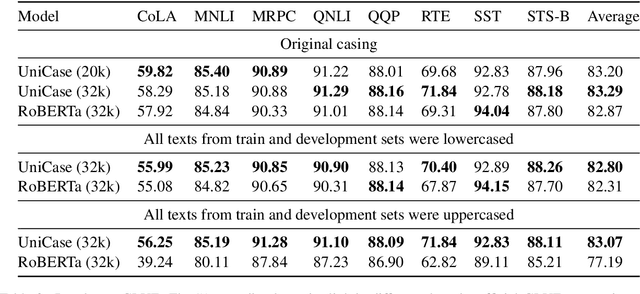
In this paper, we introduce a new approach to dealing with the problem of case-sensitiveness in Language Modelling (LM). We propose simple architecture modification to the RoBERTa language model, accompanied by a new tokenization strategy, which we named Unified Case LM (UniCase). We tested our solution on the GLUE benchmark, which led to increased performance by 0.42 points. Moreover, we prove that the UniCase model works much better when we have to deal with text data, where all tokens are uppercased (+5.88 point).
View paper on