 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGhost Loss to Question the Reliability of Training Data
Paper and Code
Sep 03, 2021


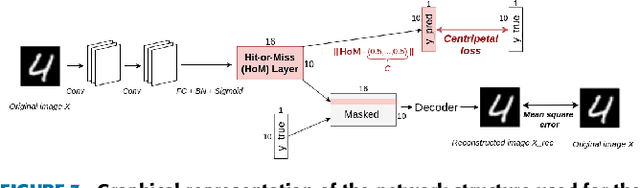
Supervised image classification problems rely on training data assumed to have been correctly annotated; this assumption underpins most works in the field of deep learning. In consequence, during its training, a network is forced to match the label provided by the annotator and is not given the flexibility to choose an alternative to inconsistencies that it might be able to detect. Therefore, erroneously labeled training images may end up ``correctly'' classified in classes which they do not actually belong to. This may reduce the performances of the network and thus incite to build more complex networks without even checking the quality of the training data. In this work, we question the reliability of the annotated datasets. For that purpose, we introduce the notion of ghost loss, which can be seen as a regular loss that is zeroed out for some predicted values in a deterministic way and that allows the network to choose an alternative to the given label without being penalized. After a proof of concept experiment, we use the ghost loss principle to detect confusing images and erroneously labeled images in well-known training datasets (MNIST, Fashion-MNIST, SVHN, CIFAR10) and we provide a new tool, called sanity matrix, for summarizing these confusions.