 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic Regression with Multimodal Large Language Models and Kolmogorov Arnold Networks
May 12, 2025We present a novel approach to symbolic regression using vision-capable large language models (LLMs) and the ideas behind Google DeepMind's Funsearch. The LLM is given a plot of a univariate function and tasked with proposing an ansatz for that function. The free parameters of the ansatz are fitted using standard numerical optimisers, and a collection of such ans\"atze make up the population of a genetic algorithm. Unlike other symbolic regression techniques, our method does not require the specification of a set of functions to be used in regression, but with appropriate prompt engineering, we can arbitrarily condition the generative step. By using Kolmogorov Arnold Networks (KANs), we demonstrate that ``univariate is all you need'' for symbolic regression, and extend this method to multivariate functions by learning the univariate function on each edge of a trained KAN. The combined expression is then simplified by further processing with a language model.
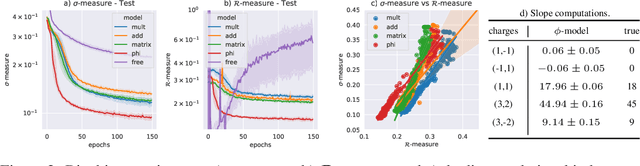
On the Learnability of Knot Invariants: Representation, Predictability, and Neural Similarity
Feb 17, 2025We analyze different aspects of neural network predictions of knot invariants. First, we investigate the impact of different knot representations on the prediction of invariants and find that braid representations work in general the best. Second, we study which knot invariants are easy to learn, with invariants derived from hyperbolic geometry and knot diagrams being very easy to learn, while invariants derived from topological or homological data are harder. Predicting the Arf invariant could not be learned for any representation. Third, we propose a cosine similarity score based on gradient saliency vectors, and a joint misclassification score to uncover similarities in neural networks trained to predict related topological invariants.
Interpretable Machine Learning for Kronecker Coefficients
Feb 17, 2025We analyze the saliency of neural networks and employ interpretable machine learning models to predict whether the Kronecker coefficients of the symmetric group are zero or not. Our models use triples of partitions as input features, as well as b-loadings derived from the principal component of an embedding that captures the differences between partitions. Across all approaches, we achieve an accuracy of approximately 83% and derive explicit formulas for a decision function in terms of b-loadings. Additionally, we develop transformer-based models for prediction, achieving the highest reported accuracy of over 99%.
Data for Mathematical Copilots: Better Ways of Presenting Proofs for Machine Learning
Dec 19, 2024

The suite of datasets commonly used to train and evaluate the mathematical capabilities of AI-based mathematical copilots (primarily large language models) exhibit several shortcomings. These limitations include a restricted scope of mathematical complexity, typically not exceeding lower undergraduate-level mathematics, binary rating protocols and other issues, which makes comprehensive proof-based evaluation suites difficult. We systematically explore these limitations and contend that enhancing the capabilities of large language models, or any forthcoming advancements in AI-based mathematical assistants (copilots or "thought partners"), necessitates a paradigm shift in the design of mathematical datasets and the evaluation criteria of mathematical ability: It is necessary to move away from result-based datasets (theorem statement to theorem proof) and convert the rich facets of mathematical research practice to data LLMs can train on. Examples of these are mathematical workflows (sequences of atomic, potentially subfield-dependent tasks that are often performed when creating new mathematics), which are an important part of the proof-discovery process. Additionally, we advocate for mathematical dataset developers to consider the concept of "motivated proof", introduced by G. P\'olya in 1949, which can serve as a blueprint for datasets that offer a better proof learning signal, alleviating some of the mentioned limitations. Lastly, we introduce math datasheets for datasets, extending the general, dataset-agnostic variants of datasheets: We provide a questionnaire designed specifically for math datasets that we urge dataset creators to include with their datasets. This will make creators aware of potential limitations of their datasets while at the same time making it easy for readers to assess it from the point of view of training and evaluating mathematical copilots.
KAN: Kolmogorov-Arnold Networks
May 02, 2024Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov-Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation functions on nodes ("neurons"), KANs have learnable activation functions on edges ("weights"). KANs have no linear weights at all -- every weight parameter is replaced by a univariate function parametrized as a spline. We show that this seemingly simple change makes KANs outperform MLPs in terms of accuracy and interpretability. For accuracy, much smaller KANs can achieve comparable or better accuracy than much larger MLPs in data fitting and PDE solving. Theoretically and empirically, KANs possess faster neural scaling laws than MLPs. For interpretability, KANs can be intuitively visualized and can easily interact with human users. Through two examples in mathematics and physics, KANs are shown to be useful collaborators helping scientists (re)discover mathematical and physical laws. In summary, KANs are promising alternatives for MLPs, opening opportunities for further improving today's deep learning models which rely heavily on MLPs.
Rigor with Machine Learning from Field Theory to the Poincaré Conjecture
Feb 20, 2024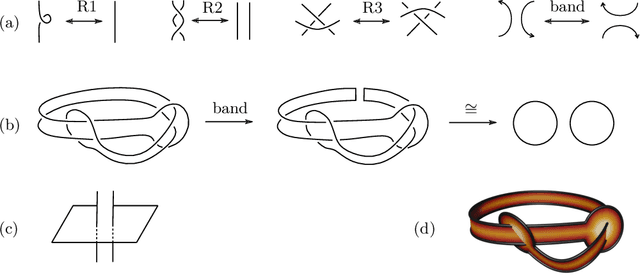
Machine learning techniques are increasingly powerful, leading to many breakthroughs in the natural sciences, but they are often stochastic, error-prone, and blackbox. How, then, should they be utilized in fields such as theoretical physics and pure mathematics that place a premium on rigor and understanding? In this Perspective we discuss techniques for obtaining rigor in the natural sciences with machine learning. Non-rigorous methods may lead to rigorous results via conjecture generation or verification by reinforcement learning. We survey applications of these techniques-for-rigor ranging from string theory to the smooth $4$d Poincar\'e conjecture in low-dimensional topology. One can also imagine building direct bridges between machine learning theory and either mathematics or theoretical physics. As examples, we describe a new approach to field theory motivated by neural network theory, and a theory of Riemannian metric flows induced by neural network gradient descent, which encompasses Perelman's formulation of the Ricci flow that was utilized to resolve the $3$d Poincar\'e conjecture.
Metric Flows with Neural Networks
Oct 30, 2023We develop a theory of flows in the space of Riemannian metrics induced by neural network gradient descent. This is motivated in part by recent advances in approximating Calabi-Yau metrics with neural networks and is enabled by recent advances in understanding flows in the space of neural networks. We derive the corresponding metric flow equations, which are governed by a metric neural tangent kernel, a complicated, non-local object that evolves in time. However, many architectures admit an infinite-width limit in which the kernel becomes fixed and the dynamics simplify. Additional assumptions can induce locality in the flow, which allows for the realization of Perelman's formulation of Ricci flow that was used to resolve the 3d Poincar\'e conjecture. We apply these ideas to numerical Calabi-Yau metrics, including a discussion on the importance of feature learning.
Searching for ribbons with machine learning
Apr 18, 2023We apply Bayesian optimization and reinforcement learning to a problem in topology: the question of when a knot bounds a ribbon disk. This question is relevant in an approach to disproving the four-dimensional smooth Poincar\'e conjecture; using our programs, we rule out many potential counterexamples to the conjecture. We also show that the programs are successful in detecting many ribbon knots in the range of up to 70 crossings.
Learning Size and Shape of Calabi-Yau Spaces
Nov 02, 2021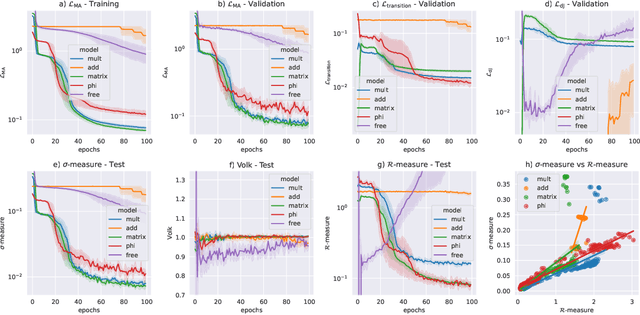
We present a new machine learning library for computing metrics of string compactification spaces. We benchmark the performance on Monte-Carlo sampled integrals against previous numerical approximations and find that our neural networks are more sample- and computation-efficient. We are the first to provide the possibility to compute these metrics for arbitrary, user-specified shape and size parameters of the compact space and observe a linear relation between optimization of the partial differential equation we are training against and vanishing Ricci curvature.
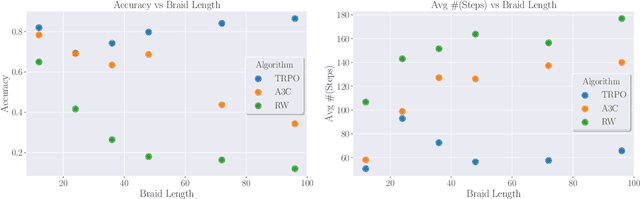
Learning to Unknot
Oct 28, 2020

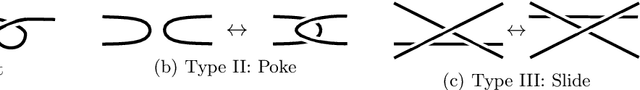

We introduce natural language processing into the study of knot theory, as made natural by the braid word representation of knots. We study the UNKNOT problem of determining whether or not a given knot is the unknot. After describing an algorithm to randomly generate $N$-crossing braids and their knot closures and discussing the induced prior on the distribution of knots, we apply binary classification to the UNKNOT decision problem. We find that the Reformer and shared-QK Transformer network architectures outperform fully-connected networks, though all perform well. Perhaps surprisingly, we find that accuracy increases with the length of the braid word, and that the networks learn a direct correlation between the confidence of their predictions and the degree of the Jones polynomial. Finally, we utilize reinforcement learning (RL) to find sequences of Markov moves and braid relations that simplify knots and can identify unknots by explicitly giving the sequence of unknotting actions. Trust region policy optimization (TRPO) performs consistently well for a wide range of crossing numbers and thoroughly outperformed other RL algorithms and random walkers. Studying these actions, we find that braid relations are more useful in simplifying to the unknot than one of the Markov moves.