 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopological Effects in Neural Network Field Theory
Apr 02, 2026Neural network field theory formulates field theory as a statistical ensemble of fields defined by a network architecture and a density on its parameters. We extend the construction to topological settings via the inclusion of discrete parameters that label the topological quantum number. We recover the Berezinskii--Kosterlitz--Thouless transition, including the spin-wave critical line and the proliferation of vortices at high temperatures. We also verify the T-duality of the bosonic string, showing invariance under the exchange of momentum and winding on $S^1$, the transformation of the sigma model couplings according to the Buscher rules on constant toroidal backgrounds, the enhancement of the current algebra at self-dual radius, and non-geometric T-fold transition functions.
Symbolic Regression with Multimodal Large Language Models and Kolmogorov Arnold Networks
May 12, 2025We present a novel approach to symbolic regression using vision-capable large language models (LLMs) and the ideas behind Google DeepMind's Funsearch. The LLM is given a plot of a univariate function and tasked with proposing an ansatz for that function. The free parameters of the ansatz are fitted using standard numerical optimisers, and a collection of such ans\"atze make up the population of a genetic algorithm. Unlike other symbolic regression techniques, our method does not require the specification of a set of functions to be used in regression, but with appropriate prompt engineering, we can arbitrarily condition the generative step. By using Kolmogorov Arnold Networks (KANs), we demonstrate that ``univariate is all you need'' for symbolic regression, and extend this method to multivariate functions by learning the univariate function on each edge of a trained KAN. The combined expression is then simplified by further processing with a language model.
Quantum Mechanics and Neural Networks
Apr 07, 2025

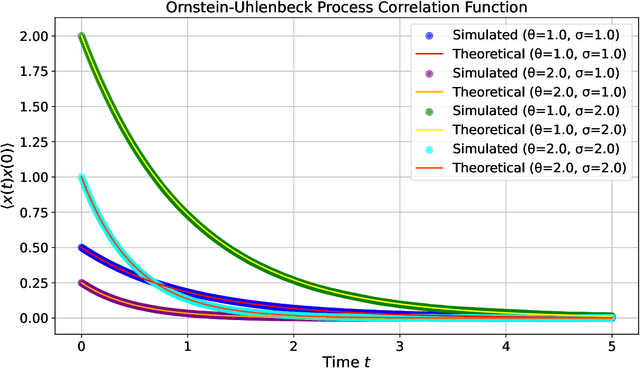

We demonstrate that any Euclidean-time quantum mechanical theory may be represented as a neural network, ensured by the Kosambi-Karhunen-Lo\`eve theorem, mean-square path continuity, and finite two-point functions. The additional constraint of reflection positivity, which is related to unitarity, may be achieved by a number of mechanisms, such as imposing neural network parameter space splitting or the Markov property. Non-differentiability of the networks is related to the appearance of non-trivial commutators. Neural networks acting on Markov processes are no longer Markov, but still reflection positive, which facilitates the definition of deep neural network quantum systems. We illustrate these principles in several examples using numerical implementations, recovering classic quantum mechanical results such as Heisenberg uncertainty, non-trivial commutators, and the spectrum.
KAN: Kolmogorov-Arnold Networks
May 02, 2024Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov-Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation functions on nodes ("neurons"), KANs have learnable activation functions on edges ("weights"). KANs have no linear weights at all -- every weight parameter is replaced by a univariate function parametrized as a spline. We show that this seemingly simple change makes KANs outperform MLPs in terms of accuracy and interpretability. For accuracy, much smaller KANs can achieve comparable or better accuracy than much larger MLPs in data fitting and PDE solving. Theoretically and empirically, KANs possess faster neural scaling laws than MLPs. For interpretability, KANs can be intuitively visualized and can easily interact with human users. Through two examples in mathematics and physics, KANs are shown to be useful collaborators helping scientists (re)discover mathematical and physical laws. In summary, KANs are promising alternatives for MLPs, opening opportunities for further improving today's deep learning models which rely heavily on MLPs.
Rigor with Machine Learning from Field Theory to the Poincaré Conjecture
Feb 20, 2024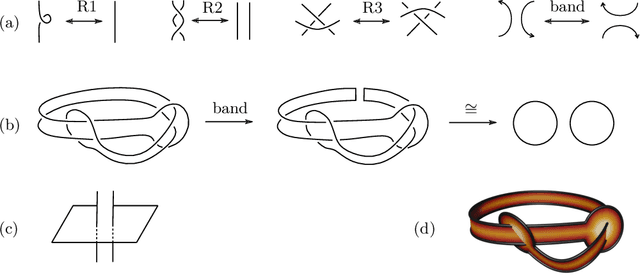
Machine learning techniques are increasingly powerful, leading to many breakthroughs in the natural sciences, but they are often stochastic, error-prone, and blackbox. How, then, should they be utilized in fields such as theoretical physics and pure mathematics that place a premium on rigor and understanding? In this Perspective we discuss techniques for obtaining rigor in the natural sciences with machine learning. Non-rigorous methods may lead to rigorous results via conjecture generation or verification by reinforcement learning. We survey applications of these techniques-for-rigor ranging from string theory to the smooth $4$d Poincar\'e conjecture in low-dimensional topology. One can also imagine building direct bridges between machine learning theory and either mathematics or theoretical physics. As examples, we describe a new approach to field theory motivated by neural network theory, and a theory of Riemannian metric flows induced by neural network gradient descent, which encompasses Perelman's formulation of the Ricci flow that was utilized to resolve the $3$d Poincar\'e conjecture.
Metric Flows with Neural Networks
Oct 30, 2023We develop a theory of flows in the space of Riemannian metrics induced by neural network gradient descent. This is motivated in part by recent advances in approximating Calabi-Yau metrics with neural networks and is enabled by recent advances in understanding flows in the space of neural networks. We derive the corresponding metric flow equations, which are governed by a metric neural tangent kernel, a complicated, non-local object that evolves in time. However, many architectures admit an infinite-width limit in which the kernel becomes fixed and the dynamics simplify. Additional assumptions can induce locality in the flow, which allows for the realization of Perelman's formulation of Ricci flow that was used to resolve the 3d Poincar\'e conjecture. We apply these ideas to numerical Calabi-Yau metrics, including a discussion on the importance of feature learning.
Neural Network Field Theories: Non-Gaussianity, Actions, and Locality
Jul 06, 2023Both the path integral measure in field theory and ensembles of neural networks describe distributions over functions. When the central limit theorem can be applied in the infinite-width (infinite-$N$) limit, the ensemble of networks corresponds to a free field theory. Although an expansion in $1/N$ corresponds to interactions in the field theory, others, such as in a small breaking of the statistical independence of network parameters, can also lead to interacting theories. These other expansions can be advantageous over the $1/N$-expansion, for example by improved behavior with respect to the universal approximation theorem. Given the connected correlators of a field theory, one can systematically reconstruct the action order-by-order in the expansion parameter, using a new Feynman diagram prescription whose vertices are the connected correlators. This method is motivated by the Edgeworth expansion and allows one to derive actions for neural network field theories. Conversely, the correspondence allows one to engineer architectures realizing a given field theory by representing action deformations as deformations of neural network parameter densities. As an example, $\phi^4$ theory is realized as an infinite-$N$ neural network field theory.
Searching for ribbons with machine learning
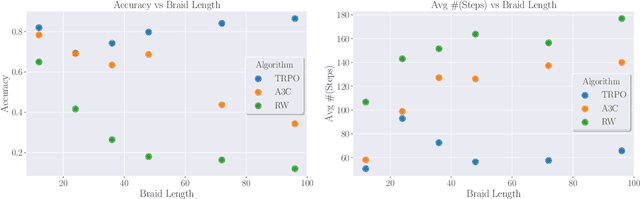
Apr 18, 2023We apply Bayesian optimization and reinforcement learning to a problem in topology: the question of when a knot bounds a ribbon disk. This question is relevant in an approach to disproving the four-dimensional smooth Poincar\'e conjecture; using our programs, we rule out many potential counterexamples to the conjecture. We also show that the programs are successful in detecting many ribbon knots in the range of up to 70 crossings.
Building Quantum Field Theories Out of Neurons
Dec 08, 2021An approach to field theory is studied in which fields are comprised of $N$ constituent random neurons. Gaussian theories arise in the infinite-$N$ limit when neurons are independently distributed, via the Central Limit Theorem, while interactions arise due to finite-$N$ effects or non-independently distributed neurons. Euclidean-invariant ensembles of neurons are engineered, with tunable two-point function, yielding families of Euclidean-invariant field theories. Some Gaussian, Euclidean invariant theories are reflection positive, which allows for analytic continuation to a Lorentz-invariant quantum field theory. Examples are presented that yield dual theories at infinite-$N$, but have different symmetries at finite-$N$. Landscapes of classical field configurations are determined by local maxima of parameter distributions. Predictions arise from mixed field-neuron correlators. Near-Gaussianity is exhibited at large-$N$, potentially explaining a feature of field theories in Nature.
Infinite Neural Network Quantum States
Dec 01, 2021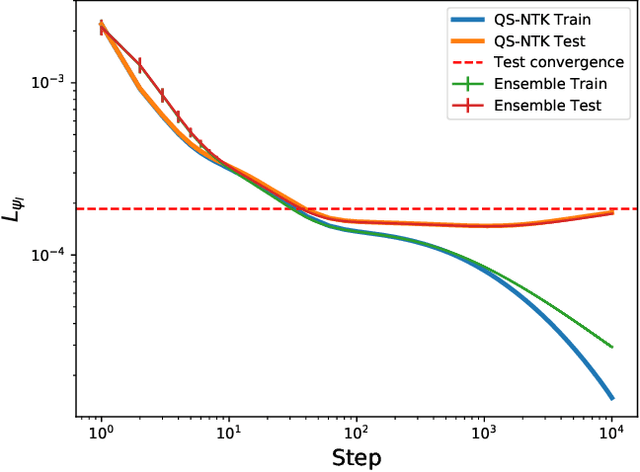

We study infinite limits of neural network quantum states ($\infty$-NNQS), which exhibit representation power through ensemble statistics, and also tractable gradient descent dynamics. Ensemble averages of Renyi entropies are expressed in terms of neural network correlators, and architectures that exhibit volume-law entanglement are presented. A general framework is developed for studying the gradient descent dynamics of neural network quantum states (NNQS), using a quantum state neural tangent kernel (QS-NTK). For $\infty$-NNQS the training dynamics is simplified, since the QS-NTK becomes deterministic and constant. An analytic solution is derived for quantum state supervised learning, which allows an $\infty$-NNQS to recover any target wavefunction. Numerical experiments on finite and infinite NNQS in the transverse field Ising model and Fermi Hubbard model demonstrate excellent agreement with theory. $\infty$-NNQS opens up new opportunities for studying entanglement and training dynamics in other physics applications, such as in finding ground states.