 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSven: Singular Value Descent as a Computationally Efficient Natural Gradient Method
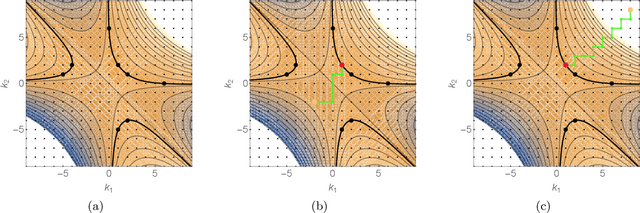
Apr 01, 2026We introduce Sven (Singular Value dEsceNt), a new optimization algorithm for neural networks that exploits the natural decomposition of loss functions into a sum over individual data points, rather than reducing the full loss to a single scalar before computing a parameter update. Sven treats each data point's residual as a separate condition to be satisfied simultaneously, using the Moore-Penrose pseudoinverse of the loss Jacobian to find the minimum-norm parameter update that best satisfies all conditions at once. In practice, this pseudoinverse is approximated via a truncated singular value decomposition, retaining only the $k$ most significant directions and incurring a computational overhead of only a factor of $k$ relative to stochastic gradient descent. This is in comparison to traditional natural gradient methods, which scale as the square of the number of parameters. We show that Sven can be understood as a natural gradient method generalized to the over-parametrized regime, recovering natural gradient descent in the under-parametrized limit. On regression tasks, Sven significantly outperforms standard first-order methods including Adam, converging faster and to a lower final loss, while remaining competitive with LBFGS at a fraction of the wall-time cost. We discuss the primary challenge to scaling, namely memory overhead, and propose mitigation strategies. Beyond standard machine learning benchmarks, we anticipate that Sven will find natural application in scientific computing settings where custom loss functions decompose into several conditions.
Decoding Nature with Nature's Tools: Heterotic Line Bundle Models of Particle Physics with Genetic Algorithms and Quantum Annealing
Jun 05, 2023The string theory landscape may include a multitude of ultraviolet embeddings of the Standard Model, but identifying these has proven difficult due to the enormous number of available string compactifications. Genetic Algorithms (GAs) represent a powerful class of discrete optimisation techniques that can efficiently deal with the immensity of the string landscape, especially when enhanced with input from quantum annealers. In this letter we focus on geometric compactifications of the $E_8\times E_8$ heterotic string theory compactified on smooth Calabi-Yau threefolds with Abelian bundles. We make use of analytic formulae for bundle-valued cohomology to impose the entire range of spectrum requirements, something that has not been possible so far. For manifolds with a relatively low number of Kahler parameters we compare the GA search results with results from previous systematic scans, showing that GAs can find nearly all the viable solutions while visiting only a tiny fraction of the solution space. Moreover, we carry out GA searches on manifolds with a larger numbers of Kahler parameters where systematic searches are not feasible.
Learning Size and Shape of Calabi-Yau Spaces
Nov 02, 2021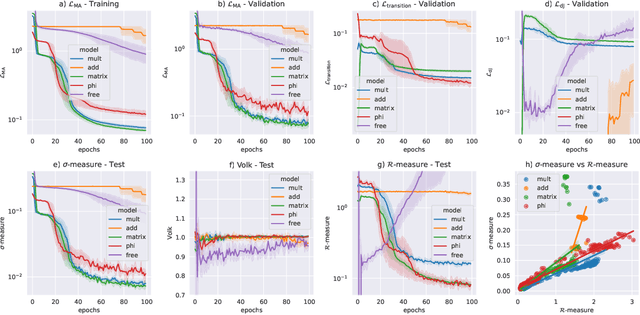
We present a new machine learning library for computing metrics of string compactification spaces. We benchmark the performance on Monte-Carlo sampled integrals against previous numerical approximations and find that our neural networks are more sample- and computation-efficient. We are the first to provide the possibility to compute these metrics for arbitrary, user-specified shape and size parameters of the compact space and observe a linear relation between optimization of the partial differential equation we are training against and vanishing Ricci curvature.
Heterotic String Model Building with Monad Bundles and Reinforcement Learning
Aug 16, 2021
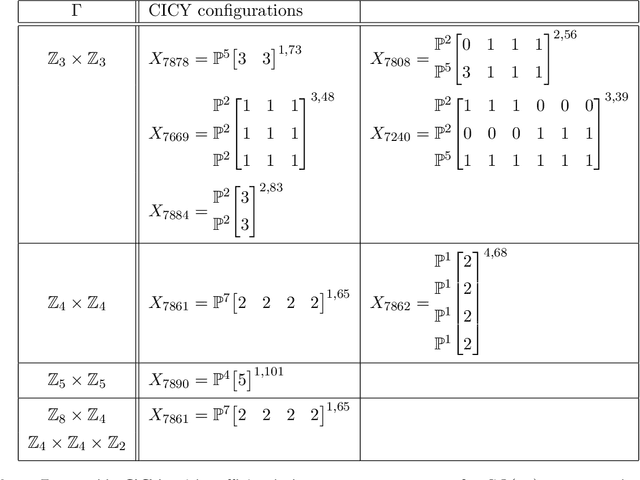

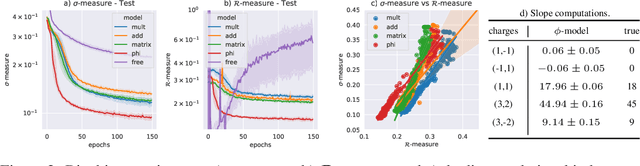
We use reinforcement learning as a means of constructing string compactifications with prescribed properties. Specifically, we study heterotic SO(10) GUT models on Calabi-Yau three-folds with monad bundles, in search of phenomenologically promising examples. Due to the vast number of bundles and the sparseness of viable choices, methods based on systematic scanning are not suitable for this class of models. By focusing on two specific manifolds with Picard numbers two and three, we show that reinforcement learning can be used successfully to explore monad bundles. Training can be accomplished with minimal computing resources and leads to highly efficient policy networks. They produce phenomenologically promising states for nearly 100% of episodes and within a small number of steps. In this way, hundreds of new candidate standard models are found.
Machine Learning Calabi-Yau Four-folds
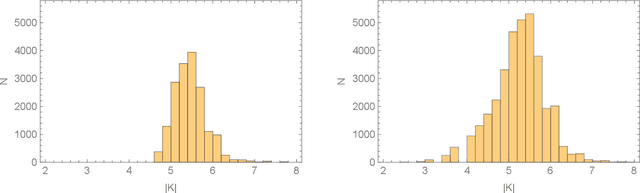
Sep 14, 2020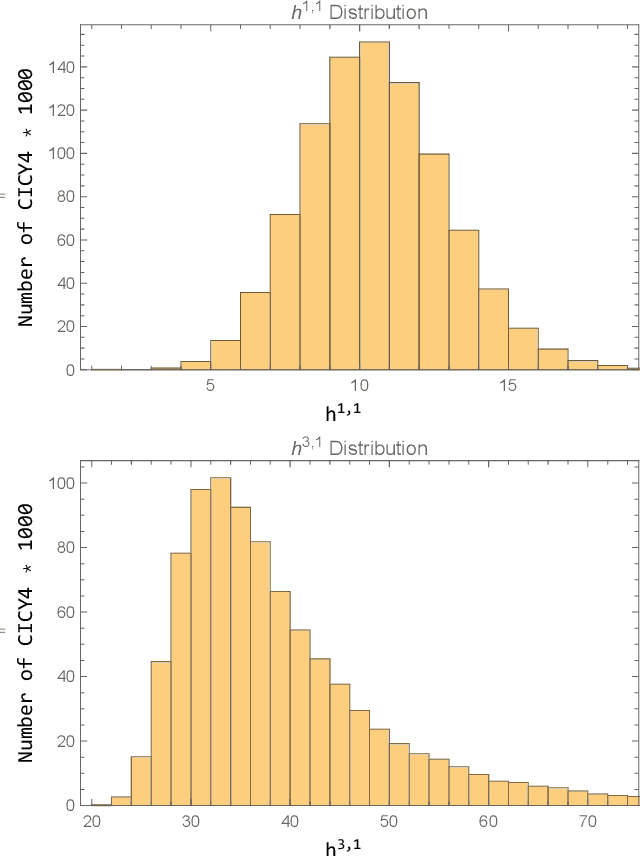
Hodge numbers of Calabi-Yau manifolds depend non-trivially on the underlying manifold data and they present an interesting challenge for machine learning. In this letter we consider the data set of complete intersection Calabi-Yau four-folds, a set of about 900,000 topological types, and study supervised learning of the Hodge numbers h^1,1 and h^3,1 for these manifolds. We find that h^1,1 can be successfully learned (to 96% precision) by fully connected classifier and regressor networks. While both types of networks fail for h^3,1, we show that a more complicated two-branch network, combined with feature enhancement, can act as an efficient regressor (to 98% precision) for h^3,1, at least for a subset of the data. This hints at the existence of an, as yet unknown, formula for Hodge numbers.
Machine Learning String Standard Models
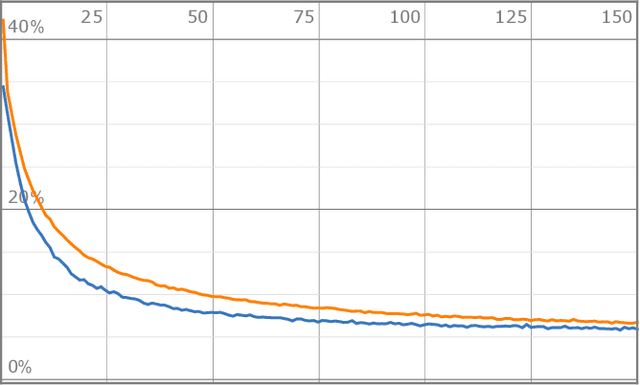
Mar 30, 2020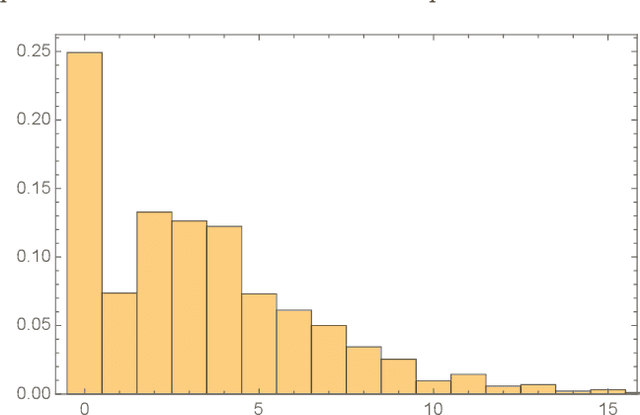

We study machine learning of phenomenologically relevant properties of string compactifications, which arise in the context of heterotic line bundle models. Both supervised and unsupervised learning are considered. We find that, for a fixed compactification manifold, relatively small neural networks are capable of distinguishing consistent line bundle models with the correct gauge group and the correct chiral asymmetry from random models without these properties. The same distinction can also be achieved in the context of unsupervised learning, using an auto-encoder. Learning non-topological properties, specifically the number of Higgs multiplets, turns out to be more difficult, but is possible using sizeable networks and feature-enhanced data sets.
* 10 pages