 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Size and Shape of Calabi-Yau Spaces
Nov 02, 2021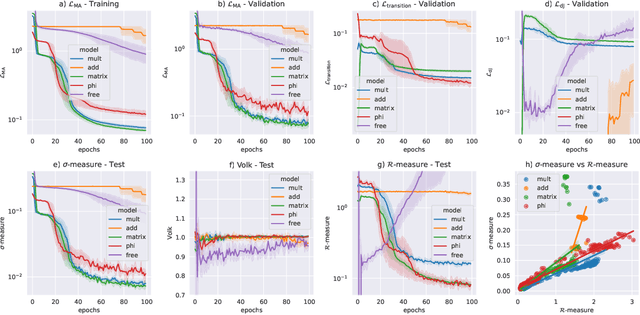
We present a new machine learning library for computing metrics of string compactification spaces. We benchmark the performance on Monte-Carlo sampled integrals against previous numerical approximations and find that our neural networks are more sample- and computation-efficient. We are the first to provide the possibility to compute these metrics for arbitrary, user-specified shape and size parameters of the compact space and observe a linear relation between optimization of the partial differential equation we are training against and vanishing Ricci curvature.
Deep multi-task mining Calabi-Yau four-folds
Aug 04, 2021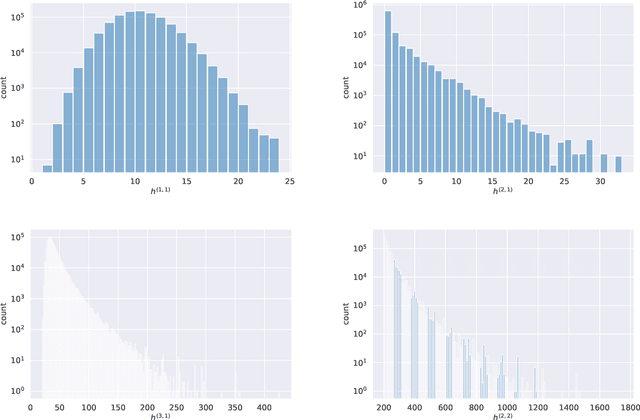
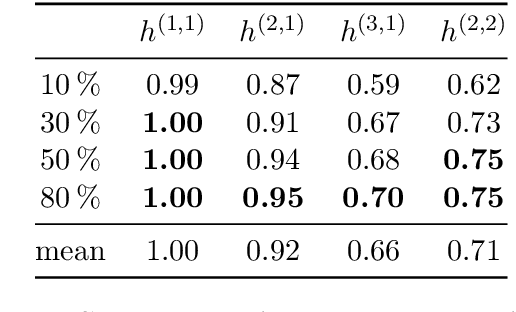
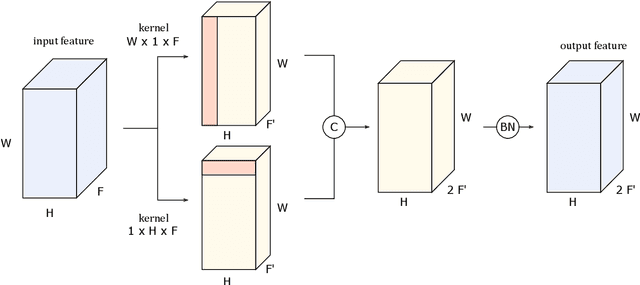
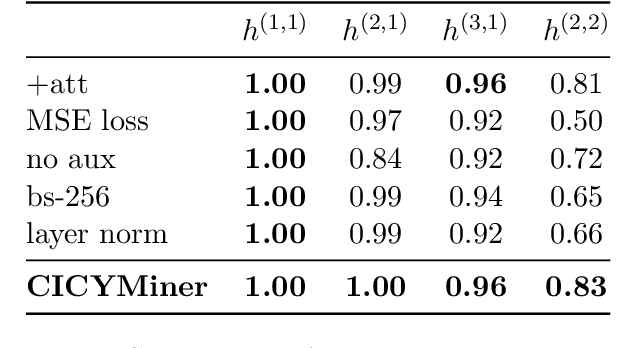
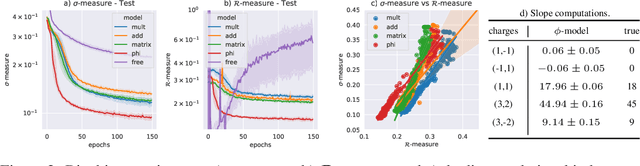
We continue earlier efforts in computing the dimensions of tangent space cohomologies of Calabi-Yau manifolds using deep learning. In this paper, we consider the dataset of all Calabi-Yau four-folds constructed as complete intersections in products of projective spaces. Employing neural networks inspired by state-of-the-art computer vision architectures, we improve earlier benchmarks and demonstrate that all four non-trivial Hodge numbers can be learned at the same time using a multi-task architecture. With 30% (80%) training ratio, we reach an accuracy of 100% for $h^{(1,1)}$ and 97% for $h^{(2,1)}$ (100% for both), 81% (96%) for $h^{(3,1)}$, and 49% (83%) for $h^{(2,2)}$. Assuming that the Euler number is known, as it is easy to compute, and taking into account the linear constraint arising from index computations, we get 100% total accuracy.
Explore and Exploit with Heterotic Line Bundle Models
Mar 10, 2020



We use deep reinforcement learning to explore a class of heterotic $SU(5)$ GUT models constructed from line bundle sums over Complete Intersection Calabi Yau (CICY) manifolds. We perform several experiments where A3C agents are trained to search for such models. These agents significantly outperform random exploration, in the most favourable settings by a factor of 1700 when it comes to finding unique models. Furthermore, we find evidence that the trained agents also outperform random walkers on new manifolds. We conclude that the agents detect hidden structures in the compactification data, which is partly of general nature. The experiments scale well with $h^{(1,1)}$, and may thus provide the key to model building on CICYs with large $h^{(1,1)}$.